一.配置ip(三个节点) 自ubuntu17之后多了一种配置方式更加高效,也就是netplan
1.1编辑配置文件
1 root@master:/etc/netplan
配置内容如下,注意缩进
1 2 3 4 5 6 7 8 9 10 11 network: version: 2 renderer: NetworkManager ethernets: ens33: dhcp4: no dhcp6: no addresses: [192.168 .10 .101 /24 ] gateway4: 192.168 .10 .1 nameservers: addresses: [8.8 .8 .8 , 192.168 .10 .1 ]
1.2使配置生效
1 root@master:/etc/netplan
如果没有报错则配置成功
二.配置主机名和主机名映射(三个节点) 1.1配置主机名并查看
1 2 3 重启后生效 root@master:/etc/netplan root@master:/etc/netplan
1.2配置主机名映射
1 root@master:/etc/netplan
添加以下内容
1 2 3 192.168.10.101 master 192.168.10.102 slave1 192.168.10.103 slave2
1.3ping测试
1 2 3 4 5 6 有以下回显证明配置成功 root@master:/etc/netplan PING slave2 (192.168.10.103) 56(84) bytes of data. 64 bytes from slave2 (192.168.10.103): icmp_seq=1 ttl=64 time=0.891 ms 64 bytes from slave2 (192.168.10.103): icmp_seq=2 ttl=64 time=0.369 ms 64 bytes from slave2 (192.168.10.103): icmp_seq=3 ttl=64 time=0.455 ms
1.4将hosts文件分发给子节点
1 2 root@master:/etc/netplan 输入yes 再输入密码
三.配置ssh免密登录(三个节点) 因为Ubuntu并不自带ssh服务所以要安装ssh并配置允许root远程登录
1 2 3 4 5 6 7 8 下载 sudo apt-get install openssh-server 启动 sudo service ssh start 配置 sudo vim /etc/ssh/sshd_config 添加一条 PermitRootLogin yes
1.生成密钥
2.将密钥写入authorized.keys文件
1 2 3 root@master:~ root@master:~/.ssh
3.在另外两个子节点执行以上操作,并将authorized.keys的内容复制进master主机的authorized.keys文件末尾,成功后如下
1 2 3 4 root@master:~/.ssh ssh-dss AAAAB3NzaC1kc3MAAACBAIzJrAXCuK15C+mq3TkdFFJUJiuY9rMo6L6LoU+naCEKJNKfRDXXAXDcRC2TJK5JqnWHuexfOusYZS/kpRU4JO1S4VGzq446r5QM19c7xH3TkE2A2W2Z9AA/7G+UHzqyHWQ6gDRIsqqsF6MlJUtOO7x3XtNUVYrtIzvUeqTbXrbJAAAAFQCsjTDCWxn2PU5WobBN/xYTxS9vdwAAAIBcM2X2tlkwnmpNcm3a1Cf4addU395AfJfhOwdqacHSCdiaNSlx7kVkd8T1Hk+gvF0KzP4KbjqiGWsGEiaYdlU4Ujrei+VplG8moa4GcCA/wUzpAioeULCP+0+870/+NwFUt7XKhYk9llUrh56LWev5c5YC3aNQ0GzElBxjUj8v4gAAAIBpUWTTkmdeL7ploxSCR56Js0pMFJiGvKP6tMkc3UL5Vwl5RDqJt+eFd31SDVJVVEK3vX06wujOlDbHwdIfpE48y2dN7nRn5bK3ccg1yo7Cq7Vtj4TlODYTkPYxXaR2e8dqW9bg8anXvaCI7AylRwPYNnQIgcjPeC4qJsRuMq4Mag== root@master ssh-dss AAAAB3NzaC1kc3MAAACBAMxF+Q5Kg1DluBqo0vZKPlE0uB2+1cDTn/f2xN0ug5mYa3WDpC36p8P2iQ4IrZEp7BqFEiQSstbZd+Im4qpaBRlHnWZhym5oOqY2a4JVsrAtyTObYFM/+/eEtQ/0Bl6UxeRKkWWPuZwbtYREEnbJ2VwLzvIJEBDVkZcccY58TO8LAAAAFQC41GJzzSEGbZLDCu2Fgzo3iml/ZQAAAIBpWqD1HHm5gTyp/6h+hCEDMP1cOOl11e+f4ZO+vhpYm+AXqpEbmMr2UTSBlc93PdJRxiIAIKidWmcLaaSuLDYWoeDDcFGCclz9bCoXZmeOVoAe096jyNFPZGorb7mqnif3oRI5hkqsmph2AX/9n90taaLUF5VrgJVEAOPLkjZ+IAAAAIEAsc7MCMYn7phJIACMypSeeWkmjUisRxVEp6u6WWHQ3GsImNkjR7UmFVxnpYOikexsPsbhlXahTIas7SQiPNRsgxi2nDBwauEvkRHQID5LbjFiIp97xbrSg8T0H23MXlBbI/MycFcyuxBIUOL5zSrz8CcUG6uQtLDMGAEVkCHORCU= root@slave1 ssh-dss AAAAB3NzaC1kc3MAAACBANwhno/+fLpWNOg1NOrBQ+qs7XWLZeu+Xxl/g5eJOD9+qaQKTWLOYfgyez38cpqjZ9r39tKRR5HQ7RVlM0tJicGgz+jCdtRoQKs6W5mc3SCmW+u+ILMxxTqdUHUKsNq4NauoVcSduq4ot8HKpi2GBGWE1MCNgCaSnH6TB8tvl49lAAAAFQCnfx5p+/KbSsrlSFo9BYuAhEuI7QAAAIA4lsxJjI3bn/FQsSjzcjIyRLiut432/i/QngE7Y9UwQGXKY9x8z7EksXDpdswo2M2cBSZsrelSnoiUYHjusSfMTptzdT8WUWCutCd7Kn1zU4fPJCM4gTNuECjHaWU/t7BVJXHGkB6eWErcHxnm6iILVLCFf9wm8oPMjRJmLLQGhQAAAIEAkA+YrcoTQfuZbS8ACHN3zkvg1/gAmx26owiZsMrSaV1rbrJ6WgWCX+Ux9CHIkKK4MZrJrXVQpoal5/PEPw0OCZepCHOGVLNcrhyhKNov1EzSC664Mb0l+9bHh+zXjv/X0yrMB1bY16eNMBCnx0YsJ5vuXZtZRg9ms6dEh5eA/LY= root@slave2
4.分发给另外两台子节点
1 2 root@master:~/.ssh root@master:~/.ssh
5.测试免密登录
1 2 3 ssh master ssh slave1 ssh slave2
四.安装jdk 1.解压
1 root@master:~/software/jdk/jdk1.8.0_11
2.分发给其余子节点
1 2 cp -r /root/software/jdk/jdk1.8.0_11/ root@slave1:/root/software/jdk/cp -r /root/software/jdk/jdk1.8.0_11/ root@slave2:/root/software/jdk/
3.配置环境变量
1 root@master:~/software/jdk/jdk1.8.0_11
配置如下
1 2 3 export JAVA_HOME=/root/software/jdk/jdk1.8.0_11export PATH=$JAVA_HOME /bin:$PATH
分发给其他节点,也可以直接配置
1 2 root@master:~/software/jdk/jdk1.8.0_11 root@master:~/software/jdk/jdk1.8.0_11
4.刷新环境变量
1 root@master:~/software/jdk/jdk1.8.0_11
5.测试
1 2 3 4 root@master:~/software/jdk/jdk1.8.0_11 java version "1.8.0_11" Java(TM) SE Runtime Environment (build 1.8.0_11-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.11-b03, mixed mode)
五.安装hadoop 1.解压
1 root@master:~/software/hadoop
2.配置环境变量
1 root@master:~/software/hadoop
配置如下
1 2 3 export HADOOP_HOME=/root/software/hadoop/hadoop-2.7.3export PATH=$HADOOP_HOME /bin:$HADOOP /sbin:$PATH
分发给子节点
1 2 root@master:~/software/hadoop root@master:~/software/hadoop
刷新环境变量
1 root@master:~/software/hadoop
3.创建hadoopdata目录
1 root@master:~/software/hadoop/hadoop-2.7.3
4.配置hadoop-env.sh文件
1 2 root@master:~/software/hadoop/hadoop-2.7.3/etc/hadoop root@master:~/software/hadoop/hadoop-2.7.3/etc/hadoop
1 2 3 4 找到 export JAVA_HOME=${JAVA_HOME} 修改为 export JAVA_HOME=/root/software/jdk/jdk1.8.0_11
5.配置yarn-env.sh
1 root@master:~/software/hadoop/hadoop-2.7.3/etc/hadoop
1 2 3 4 找到 修改为 export JAVA_HOME=/root/software/jdk/jdk1.8.0_11
6.配置核心组件core-site.xml
1 root@master:~/software/hadoop/hadoop-2.7.3/etc/hadoop
1 2 3 4 5 6 7 8 9 10 <configuration > <property > <name > fs.defaultFS</name > <value > hdfs://master:9000</value > </property > <property > <name > hadoop.tmp.dir</name > <value > /root/software/hadoop/hadoop-2.7.3/hadoopdata</value > </property > </configuration >
7.配置配置文件系统hdfs-site.xml
1 root@master:~/software/hadoop/hadoop-2.7.3/etc/hadoop
1 2 3 4 5 6 7 8 9 10 <configuration > <property > <name > dfs.replication</name > <value > 2</value > </property > <property > <name > dfs.namenode.rpc-address</name > <value > master:50071</value > </property > </configuration >
8.配置文件系统yarn-site.xm
1 root@master:~/software/hadoop/hadoop-2.7.3/etc/hadoop
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 <configuration > <property > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > </property > <property > <name > yarn.resourcemanager.address</name > <value > master:18040</value > </property > <property > <name > yarn.resourcemanager.scheduler.address</name > <value > master:18030</value > </property > <property > <name > yarn.resourcemanager.resource-tracker.address</name > <value > master:18025</value > </property > <property > <name > yarn.resourcemanager.admin.address</name > <value > master:18141</value > </property > <property > <name > yarn.resourcemanager.webapp.address</name > <value > master:18088</value > </property > </configuration >
9.配置计算框架mapred-site.xml
1 2 3 root@master:~/software/hadoop/hadoop-2.7.3/etc/hadoop root@master:~/software/hadoop/hadoop-2.7.3/etc/hadoop
1 2 3 4 5 6 <configuration > <property > <name > mapreduce.framework.name</name > <value > yarn</value > </property > </configuration >
10.配置slaves文件
1 root@master:~/software/hadoop/hadoop-2.7.3/etc/hadoop
11.分发给子节点
1 root@master:~/software/hadoop/hadoop-2.7.3/etc/hadoop
12.格式化namanode
1 root@master:~/software/hadoop/hadoop-2.7.3/etc/hadoop
13.启动hadoop
1 2 3 4 5 进入sbin目录下执行 root@master:~/software/hadoop/hadoop-2.7.3/sbin 执行命令后,提示出入yes /no时,输入yes 。
14.测试
1 root@master:~/software/hadoop/hadoop-2.7.3/sbin
有以下进程表示搭建成功!
1 2 3 4 5 6 7 root@master:~/software/hadoop/hadoop-2.7.3/sbin 4848 SecondaryNameNode 4999 ResourceManager 4489 NameNode 4650 DataNode 5423 Jps 5135 NodeManager
15.web端查看
1 在Master上启动Firefox浏览器,在浏览器地址栏中输入输入http://master:50070/,有如下回显表示成功
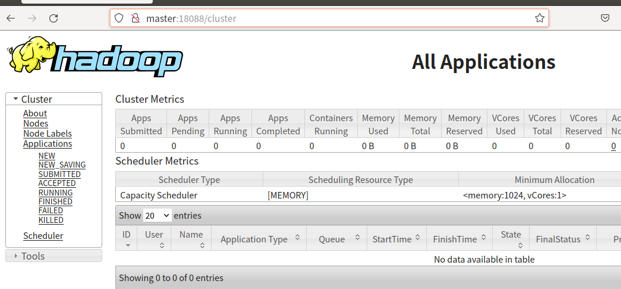
1 在Master上启动Firefox浏览器,在浏览器地址栏中输入输入http://master:18088/,检查 Yarn是否正常,页面如下图所示。
六.flume安装与配置 1.解压
1 tar -zxvf apache-flume-1.7.0-bin.tar.gz
2.配置环境变量
1 2 3 export FLUME_HOME=/root/software/flume-1.7.0export PATH=$FLUME_HOME /bin:$PATH
3.复制配置文件
1 cp flume-env.sh.template flume-env.sh
修改
1 2 export JAVA_HOME=/root/software/jdk1.8.0_11
4.配置配置文件
1 2 3 4 5 source : 数据的入口,规定了数据收集的入口规范channel: 管道,存储数据用的 skin: 数据的出口,规定了数据收集的出口规范 agent: 一个任务,包含了source ,channel,skin
1 cp flume-conf.properties.template flume-conf.properties
修改为
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 a1.sinks.k1.type = logger a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
5.启动
1 ./bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties --name a1 -Dflume.root.logger=INFO,console
6.nc测试
7.案例一
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 a1.sources = s1 a1.sinks = k1 a1.channels = c1 a1.sources.s1.type = exec a1.sources.s1.command = tail -F /tmp/log.txt a1.sources.s1.bash = /bin/bash -c a1.sources.s1.channels = c1 a1.sinks.k1.type = logger a1.sinks.k1.channel = c1 a1.channels.c1.type = memory
8.案例二
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = netcat a1.sources.r1.bind = 192.168.32.130 a1.sources.r1.port = 44444 a1.sinks.k1.type = logger a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transctionCapacity = 100 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
9.案例三
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 a1.sources = s1 a1.sinks = k1 a1.channels = c1 a1.sources.s1.type =spooldir a1.sources.s1.spoolDir =/tmp/logs a1.sources.s1.basenameHeader = true a1.sources.s1.basenameHeaderKey = fileName a1.sources.s1.channels =c1 a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H/ a1.sinks.k1.hdfs.filePrefix = %{fileName} a1.sinks.k1.hdfs.fileType = DataStream a1.sinks.k1.hdfs.useLocalTimeStamp = true a1.sinks.k1.channel = c1 a1.channels.c1.type = memory
10.案例四
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 a1.sources = s1 a1.sinks = k1 a1.channels = c1 a1.sources.s1.type = exec a1.sources.s1.command = tail -F /tmp/log.txt a1.sources.s1.bash = /bin/bash -c a1.sources.s1.channels = c1 a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop001 a1.sinks.k1.port = 8888 a1.sinks.k1.batch-size = 1 a1.sinks.k1.channel = c1 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100
配置日志聚合Flume
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 a2.sources = s2 a2.sinks = k2 a2.channels = c2 a2.sources.s2.type = avro a2.sources.s2.bind = hadoop001 a2.sources.s2.port = 8888 a2.sources.s2.channels = c2 a2.sinks.k2.type = logger a2.sinks.k2.channel = c2 a2.channels.c2.type = memory a2.channels.c2.capacity = 1000 a2.channels.c2.transactionCapacity = 100
这里建议先启动a2,原因是 avro.source 会先与端口进行绑定,这样 avro sink 连接时才不会报无法连接的异常。但是即使不按顺序启动也是没关系的,sink 会一直重试,直至建立好连接。
七.Zookeeper安装配置 1.解压并配置环境变量
1 2 3 export ZOOKEEPER_HOME=/root/software/zookeeper-3.4.5-cdh5.6.0export PATH=$ZOOKEEPER_HOME /bin:$PATH
2.新建一个目录用来存放数据
1 mkdir /root/software/zookeeper-3.4.5-cdh5.6.0/zk_data
3.编辑配置文件
1 cp zoo_sample.cfg zoo.cfg
1 dataDir=/root/software/zookeeper-3.4.5-cdh5.6.0/zk_data
4.启动
八.kafka安装配置与使用 1.解压并配置环境变量
1 2 3 export KAFKA_HOME=/root/software/kafka_2.11-2.0.0export PATH=$KAFKA_HOME /bin:$PATH
2.创建日志文件夹
1 mkdir /root/software/kafka_2.11-2.0.0/kafka-logs
3.config文件夹中修改配置文件以下几项
1 2 3 log.dirs=/root/software/kafka_2.11-2.0.0/kafka-logs listeners=PLAINTEXT://localhost:9092
4.启动kafka
1 kafka-server-start.sh ./config/server.properties
5.创建topic主题
1 kafka-topics.sh --zookeeper localhost: 2181/kafka --create --topic topic-demo --replication-factor 1 --partitions 1
6.查看
1 kafka-topics.sh --list --zookeeper localhost:2181
7.生产消息
1 kafka-console-producer.sh --broker-list localhost:9092 --topic topic-demo
8.消费消息
1 2 kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic-demo --beginning 可选参数,代表从头消费
9.查看所有topic的信息
1 2 kafka-topics.sh --zookeeper localhost: 2181 --describe --topic topic-demo 可选参数,表示指定topic
10.单节点多broker
修改配合文件中的id,端口,日志文件夹
启动1 2 3 kafka-server-start.sh --deamon ./config/server.properties & kafka-server-start.sh --deamon ./config/server2.properties & kafka-server-start.sh --deamon ./config/server3.properties &
多副本1 kafka-topics.sh --zookeeper localhost: 2181/kafka --create --topic my-topic-demo --replication-factor 3 --partitions 1
九.安装scala 1.解压并配置环境变量
1 2 root@ubuntu:~/software/scala-2.11.0 root@ubuntu:~/software/scala-2.11.0
1 2 3 export SCALA_HOME=/root/software/scala-2.11.0export PATH=$SCALA_HOME /bin:$PATH
2.刷新环境变量
1 root@ubuntu:~/software/scala-2.11.0
3.测试
1 2 3 4 5 6 root@ubuntu:~/software/scala-2.11.0 Welcome to Scala version 2.11.0 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_11). Type in expressions to have them evaluated. Type :help for more information. scala>
十.安装maven 1.解压并配置环境变量
1 2 3 root@ubuntu:~/software root@ubuntu:~/software root@ubuntu:~/software
1 2 3 export MAVEN_HOME=/root/software/maven-3.8.5export PATH=$MAVEN_HOME /bin:$PATH
2.刷新环境变量
1 root@ubuntu:~/software/scala-2.11.0
3.测试
1 2 3 4 5 6 root@ubuntu:~/software/maven-3.8.5 Apache Maven 3.8.5 (3599d3414f046de2324203b78ddcf9b5e4388aa0) Maven home: /root/software/maven-3.8.5 Java version: 1.8.0_11, vendor: Oracle Corporation, runtime: /root/software/jdk1.8.0_11/jre Default locale: en_US, platform encoding: UTF-8 OS name: "linux" , version: "5.4.0-100-generic" , arch : "amd64" , family: "unix"
4.修改jar包存放位置
1 2 root@ubuntu:~/software/maven-3.8.5 root@ubuntu:~/software/maven-3.8.5
添加一行
1 <localRepository > /root/software/maven-3.8.5/maven-repos</localRepository >
十一.Hbase安装 1.解压并配置环境变量
1 2 root@master:~/software root@ubuntu:~/software
1 2 3 export HBASE_HOME=/root/software/hbase-1.2.0export PATH=$HBASE_HOME /bin:$PATH
2.刷新环境变量
3.编辑配置文件
1 root@master:~/software/hbase-1.2.0/conf
修改
1 2 export JAVA_HOME=/root/software/jdk1.8.0_11
修改
1 2 export HBASE_MANAGES_ZK=false
添加
1 root@master:~/software/hbase-1.2.0/conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 <configuration > <property > <name > hbase.cluster.distributed</name > </property > <property > <name > hbase.rootdir</name > <value > hdfs://master:9000/hbase</value > </property > <property > <name > hbase.zookeeper.quorum</name > <value > master</value > </property > <property > <name > hbase.master.info.port</name > <value > 60010</value > </property > </configuration >
修改
1 root@master:~/software/hbase-1.2.0/conf
为
4.启动hbase
1 2 3 4 root@master:~/software JMX enabled by default Using config: /root/software/zookeeper-3.4.5-cdh5.6.0/bin/../conf/zoo.cfg Starting zookeeper ... STARTED
1 2 3 4 5 6 7 root@master:~/software starting master, logging to /root/software/hbase-1.2.0/logs/hbase-root-master-master.out Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0 Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0 master: starting regionserver, logging to /root/software/hbase-1.2.0/bin/../logs/hbase-root-regionserver-master.out master: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0 master: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
1 2 3 4 5 6 7 8 9 10 root@master:~/software/hbase-1.2.0/bin 2992 SecondaryNameNode 4514 QuorumPeerMain 3282 NodeManager 6196 HRegionServer 3143 ResourceManager 6026 HMaster 6330 Jps 2636 NameNode 2796 DataNode
访问
6.测试
1 2 3 4 root@master:~/software/hbase-1.2.0/bin hbase(main):001:0> version 1.2.0, r25b281972df2f5b15c426c8963cbf77dd853a5ad, Thu Feb 18 23:01:49 CST 2016
十二.Spark安装 1.解压并配置环境变量
1 2 root@master:~/software root@ubuntu:~/software
1 2 3 export SPARK_HOME=/root/software/spark-2.1.1-bin-hadoop2.7export PATH=$SPARK_HOME /bin:$PATH
2.刷新环境变量
3.测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 root@master:~/software/spark-2.1.1-bin-hadoop2.7 Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.1.1 /_/ Using Scala version 2.11.8, Java HotSpot(TM) 64-Bit Server VM, 1.8.0_11 Branch Compiled by user jenkins on 2017-04-25T23:51:10Z Revision Url Type --help for more information.
十三.flume对接kafka 一般flume采集的方式有两种
1 2 a1.sources.r1.type = exec a1.sources.r1.command = tail -F /tmp/log.txt //此处输入命令
2.Spooling Directory类型的 Source
1 2 a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /home/work/data
1.flume采集某日志文件到kafka自定义topic 1.1 创建flume配置文件 flume-kafka-file.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = exec a1.sources.r1.command = tail -F /tmp/log.txt a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.kafka.topic = topic-test a1.sinks.k1.kafka.bootstrap.servers = localhost:9092 a1.sinks.k1.kafka.flumeBatchSize = 20 a1.sinks.k1.kafka.producer.acks = 1 a1.sinks.k1.kafka.producer.linger.ms = 1 a1.sinks.ki.kafka.producer.compression.type = snappy a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
1.2 启动zookeeper和kafka
1 2 3 4 ./zkServer.sh start JMX enabled by default Using config: /root/software/zookeeper-3.4.5-cdh5.6.0/bin/../conf/zoo.cfg Starting zookeeper ... already running as process 5452.
1 kafka-server-start.sh ./config/server.properties
1.3 创建topic
topic:指定topic name
partitions:指定分区数,这个参数需要根据broker数和数据量决定,正常情况下,每个broker上两个partition最好
replication-factor:副本数,建议设置为2
1 kafka-topics.sh --zookeeper localhost: 2181/kafka --create --topic topic-test2 --replication-factor 1 --partitions 1
1.4 启动kafka去消费topic
1 2 kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic-test2 --from-beginning 可选参数,代表从头消费
1.5 启动flume
1 ./bin/flume-ng agent -n a1 -c ./conf/ -f ./conf/flume-kafka-port.conf -Dflume.root.logger=INFO,console
1.6 向日志文件/tmp/log.txt写入一些数据
1 echo '123' >> /tmp/log.txt
就可以在消费者窗口看到输出
2.flume采集端口数据到kafka自定义topic 2.1 新建配置文件 flume-kafka-port.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 55555 a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.kafka.topic = topic-test2 a1.sinks.k1.kafka.bootstrap.servers = localhost:9092 a1.sinks.k1.kafka.flumeBatchSize = 20 a1.sinks.k1.kafka.producer.acks = 1 a1.sinks.k1.kafka.producer.linger.ms = 1 a1.sinks.ki.kafka.producer.compression.type = snappy a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
2.2所有操作与上文一致
2.3 向端口发送数据
1 2 3 4 5 6 7 8 9 10 11 root@ubuntu:~ OK ls OK ls OK ls OK ls OK ls
在消费者端口可以看到