创建项目 1 scrapy startproject tutorial
创建任务 1 scrapy genspider first www.baidu.com
会生成一个first文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import scrapyclass FirstSpider (scrapy.Spider): name = 'first' allowed_domains = ['www.baidu.com' ] start_urls = ['https://www.baidu.com/' ] def parse (self, response ): pass
修改配置文件 只输出ERROR级别的日志
不遵从robots协议
指定ua
1 USER_AGENT = 'tutorial (+http://www.yourdomain.com)'
运行程序 会输出一个response对象
1 <200 https:// www.baidu.com/>
数据解析 1 2 3 4 5 6 7 8 9 10 11 12 13 import scrapyclass FirstSpider (scrapy.Spider): name = 'first' start_urls = ['https://ishuo.cn/' ] def parse (self, response ): title_list = response.xpath('//*[@id="list"]/ul/li/div[1]/text()' ) for title in title_list: print (title)
可以看到返回了一个selector对象,我们想要的数据在data属性里
1 2 3 4 chenci@MacBook-Pro tutorial %scrapy crawl first <Selector xpath='//*[@id="list"]/ul/li/div[1]/text()' data='如果你得罪了老板,失去的只是一份工作;如果你得罪了客户,失去的不过是一份订...' > <Selector xpath='//*[@id="list"]/ul/li/div[1]/text()' data='有位非常漂亮的女同事,有天起晚了没有时间化妆便急忙冲到公司。结果那天她被记...' > <Selector xpath='//*[@id="list"]/ul/li/div[1]/text()' data='悟空和唐僧一起上某卫视非诚勿扰,悟空上台,24盏灯全灭。理由:1.没房没车...' >
从data属性中取出我们想要的数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import scrapyclass FirstSpider (scrapy.Spider): name = 'first' start_urls = ['https://ishuo.cn/' ] def parse (self, response ): title_list = response.xpath('//*[@id="list"]/ul/li/div[1]/text()' ) for title in title_list: title = title.extract() print (title)
持久化存储 1.基于终端指令的存储 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import scrapyclass FirstSpider (scrapy.Spider): name = 'first' start_urls = ['https://ishuo.cn/' ] def parse (self, response ): data_all = [] title_list = response.xpath('//*[@id="list"]/ul/li/div[1]/text()' ) for title in title_list: title = title.extract() dic = { 'title' : title } data_all.append(dic) return data_all
执行
1 chenci@MacBook-Pro tutorial %scrapy crawl first -o test.csv
2.基于管道的持久化存储 开启管道
settings.py
1 2 3 ITEM_PIPELINES = { 'tutorial.pipelines.TutorialPipeline' : 300 , }
在items.py中定义相关属性
1 2 3 4 5 6 7 8 9 import scrapyclass TutorialItem (scrapy.Item): title = scrapy.Field()
将first.py提取出的数据提交给管道
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import scrapyfrom tutorial.items import TutorialItemclass FirstSpider (scrapy.Spider): name = 'first' start_urls = ['https://ishuo.cn/' ] def parse (self, response ): title_list = response.xpath('//*[@id="list"]/ul/li/div[1]/text()' ) for title in title_list: title = title.extract() item = TutorialItem() item['title' ] = title yield item
在pipelines.py中重写父类方法,存储到本地
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class TutorialPipeline : f = None def open_spider (self, spider ): print ('我是open_spider,只会在爬虫开始的时候执行一次' ) self.f = open ('./text1.txt' , 'w' , encoding='utf-8' ) def close_spider (self, spider ): print ('我是close_spider,只会在爬虫开始的时候执行一次' ) self.f.close() def process_item (self, item, spider ): self.f.write(item['title' ] + '\n' ) return item
基于管道实现数据的备份
pipelines.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import pymysqlclass MysqlPipeline (object ): conn = None cursor = None def open_spider (self, spider ): self.conn = pymysql.Connect(host='localhost' , port=3306 , user='root' , password='123456' , charset='utf8' , db='spider' ) def process_item (self, item, spider ): self.cursor = self.conn.cursor() sql = 'insert into duanzi values("%s")' % item['title' ] try : self.cursor.execute(sql) self.conn.commit() except Exception as e: print (e) self.conn.rollback() return item def close_spider (self, spider ): self.cursor.close() self.conn.close()
在settings.py增加一个管道
1 2 3 4 5 ITEM_PIPELINES = { 'tutorial.pipelines.TutorialPipeline' : 300 , 'tutorial.pipelines.MysqlPipeline' : 301 , }
手动请求发送 新建工程
1 2 3 chenci@MacBook-Pro scrapy %scrapy startproject HandReq chenci@MacBook-Pro scrapy %cd HandReq chenci@MacBook-Pro HandReq %scrapy genspider duanzi www.xxx.com
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import scrapyfrom HandReq.items import HandreqItemclass DuanziSpider (scrapy.Spider): name = 'duanzi' start_urls = ['https://duanzixing.com/page/1/' ] url = 'https://duanzixing.com/page/%d/' page_num = 2 def parse (self, response ): title_list = response.xpath('/html/body/section/div/div/article[1]/header/h2/a/text()' ) for title in title_list: title = title.extract() item = HandreqItem() item['title' ] = title yield item if self.page_num < 5 : new_url = format (self.url % self.page_num) self.page_num += 1 yield scrapy.Request(url=new_url, callback=self.parse)
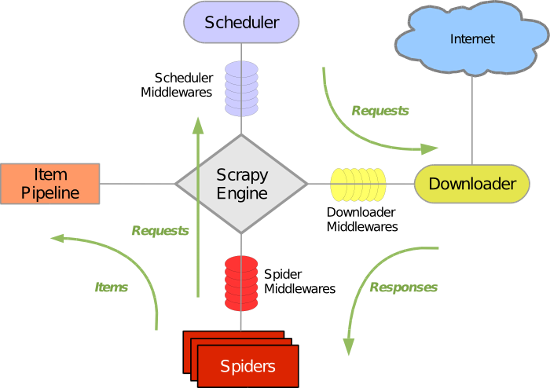
五大核心组件工作流程
引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心)
调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
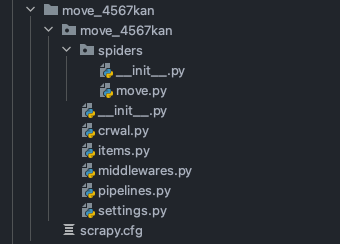
请求传参的深度爬取-4567kan.com 文件目录
meta是一个字典,可以将meta传给callback
scrapy.Request(url, callback, meta)
callback取出字典
item = response.meta['item']
move.py 项目文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 import scrapyfrom move_4567kan.items import Move4567KanItemclass MoveSpider (scrapy.Spider): name = 'move' start_urls = ['https://www.4567kan.com/frim/index1-1.html' ] url = 'https://www.4567kan.com/frim/index1-%d.html' page_num = 2 def parse (self, response ): li_list = response.xpath('/html/body/div[2]/div/div[3]/div/div[2]/ul/li' ) for li in li_list: url = 'https://www.4567kan.com' + li.xpath('./div/a/@href' ).extract()[0 ] title = li.xpath('./div/a/@title' ).extract()[0 ] item = Move4567KanItem() item['title' ] = title yield scrapy.Request(url=url, callback=self.get_details, meta={'item' : item}) if self.page_num < 5 : new_url = format (self.url % self.page_num) self.page_num += 1 yield scrapy.Request(url=new_url, callback=self.parse) def get_details (self, response ): details = response.xpath('//*[@class="detail-content"]/text()' ).extract() if details: details = details[0 ] else : details = None item = response.meta['item' ] item['details' ] = details yield item
items.py 定义两个字段
1 2 3 4 5 6 7 8 9 import scrapyclass Move4567KanItem (scrapy.Item): title = scrapy.Field() details = scrapy.Field()
pipelines.py 打印输出
1 2 3 4 5 class Move4567KanPipeline : def process_item (self, item, spider ): print (item) return item
中间件 作用
拦截请求和响应
爬虫中间件
略
下载中间件(推荐)
拦截请求:
1.篡改请求url
2.伪装请求头信息:
UA
Cookie
3.设置请求代理
拦截响应:
篡改响应数据
改写中间件文件 middlewares.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from scrapy import signalsfrom itemadapter import is_item, ItemAdapterclass MiddleDownloaderMiddleware : def process_request (self, request, spider ): print ('我是process_request()' ) return None def process_response (self, request, response, spider ): print ('我是process_response()' ) return response def process_exception (self, request, exception, spider ): print ('我是process_exception()' )
编写爬虫文件
1 2 3 4 5 6 7 8 9 10 11 import scrapyclass MidSpider (scrapy.Spider): name = 'mid' start_urls = ['https://www.baidu.com' , 'https://www.sogou.com' ] def parse (self, response ): print (response)
在配置文件setting.py中启用
1 2 3 4 5 ROBOTSTXT_OBEY = True DOWNLOADER_MIDDLEWARES = { 'middle.middlewares.MiddleDownloaderMiddleware' : 543 , }
启动工程
1 2 3 4 5 6 7 chenci@MacBook-Pro middle %scrapy crawl mid 我是process_request() 我是process_request() 我是process_response() 我是process_exception() 我是process_response() 我是process_exception()
process_exception()方法设置代理
1 2 3 4 5 6 7 8 9 10 def process_exception (self, request, exception, spider ): request.meta['proxy_' ] = 'https://ip:port' print ('我是process_exception()' ) return request
process_request()方法设置headers
1 2 3 4 5 6 def process_request (self, request, spider ): request.headers['User-Agent' ] = 'xxx' request.headers['Cookie' ] = 'xxx' print ('我是process_request()' ) return None
process_response()方法篡改响应数据
1 2 3 4 5 6 7 def process_response (self, request, response, spider ): response.text = 'xxx' print ('我是process_response()' ) return response
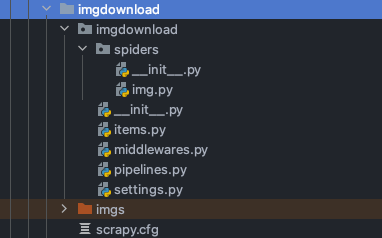
大文件下载-爬取jdlingyu.com图片 文件目录
img.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import scrapyfrom imgdownload.items import ImgdownloadItemclass ImgSpider (scrapy.Spider): name = 'img' start_urls = ['https://www.jdlingyu.com' ] def parse (self, response ): li_list = response.xpath('/html/body/div[1]/div[2]/div[1]/div/div[6]/div/div[1]/div/div[2]/ul/li' ) for a in li_list: url = a.xpath('./div/div[2]/h2/a/@href' ).extract()[0 ] title = a.xpath('./div/div[2]/h2/a/text()' ).extract()[0 ] item = ImgdownloadItem() item['title' ] = title yield scrapy.Request(url=url, callback=self.get_img_url, meta={'item' : item}) def get_img_url (self, response ): page = 0 item = response.meta['item' ] img_list = response.xpath('//*[@id="primary-home"]/article/div[2]/img' ) for scr in img_list: img_url = scr.xpath('./@src' ).extract()[0 ] page += 1 item['img_url' ] = img_url item['page' ] = page yield item
setting.py增加配置
1 2 3 4 5 6 USER_AGENT = 'ua' ROBOTSTXT_OBEY = False LOG_LEVEL = 'ERROR' IMAGES_STORE = './imgs'
items.py增加字段
1 2 3 4 5 6 7 8 9 import scrapyclass ImgdownloadItem (scrapy.Item): title = scrapy.Field() img_url = scrapy.Field() page = scrapy.Field()
pipelines.py增加管道类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import scrapyfrom itemadapter import ItemAdapterclass ImgdownloadPipeline : def process_item (self, item, spider ): return item from scrapy.pipelines.images import ImagesPipelineclass img_download (ImagesPipeline ): def get_media_requests (self, item, info ): yield scrapy.Request(url=item['img_url' ], meta={'title' : item['title' ], 'page' : item['page' ]}) def file_path (self, request, response=None , info=None , *, item=None ): title = request.meta['title' ] page = request.meta['page' ] path = f'{title} /{page} .jpg' return path def item_completed (self, results, item, info ): return item
setting.py增加管道类
1 2 3 4 ITEM_PIPELINES = { 'imgdownload.pipelines.img_download' : 300 , }
运行效果
CrawlSpider 深度爬取 是什么
是Spider的一个子类,也就是爬虫文件的父类
作用:用作于全站数据的爬取
将一个页面下所有的页码进行爬取
基本使用
1.创建一个工程
2.创建一个基于CrawlSpider类的爬虫文件
crapy genspider -t crawl main www.xxx.com
3.执行工程
编写工程文件main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import scrapyfrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Ruleclass MainSpider (CrawlSpider ): name = 'main' start_urls = ['https://www.mn52.com/fj/' ] rules = ( Rule(LinkExtractor(allow=r'list_8_\d.html' ), callback='parse_item' , follow=True ), ) def parse_item (self, response ): print (response) item = {} return item
执行工程
可以看到抓取了所有页码的url
1 2 3 4 5 6 7 8 9 chenci@MacBook-Pro crawl %scrapy crawl main <200 https://www.mn52.com/fj/list_8_2.html> <200 https://www.mn52.com/fj/list_8_3.html> <200 https://www.mn52.com/fj/list_8_4.html> <200 https://www.mn52.com/fj/list_8_8.html> <200 https://www.mn52.com/fj/list_8_5.html> <200 https://www.mn52.com/fj/list_8_7.html> <200 https://www.mn52.com/fj/list_8_9.html> <200 https://www.mn52.com/fj/list_8_6.html>