华为HCIA
大数据概述&解决办法
大数据的特征(5v+1c)
- 大量:数据量巨大,MB,GB,TB,PB
- 多样:数据类型多样,数据来源多样 数据来源:服务器日志、网站浏览信息、社交
结构化数据:表格数据 平台、摄像头信息
半结构化数据:网页html、xml
非结构化数据:视频、音频、图片、文字 - 高速:数据产生速度快、数据处理速度快
- 价值:价值密度低
- 准确:数据真实性
- 复杂:数据产生速度快、数据的类型多样等特征,导致做数据处理时处理过程变得很复杂
大数据处理流程
数据采集->数据预处理->数据存储->分析挖掘->数据可视化
大数据任务类型
- IO密集型任务:大量输入输出请求的任务IO资源
- 计算密集型任务:有大量的计算要求,CPU资源
- 数据密集型任务:数据处理,并发数据处理
大数据的计算类型(数据处理类型)
- 批处理:一次处理一批量数据,处理的数据量大,但是延迟性高
- 流处理:一次处理一条数据,处理的数据量小,但是延迟性低
- 图处理:以图的形式展示数据,进行处理
- 查询分析计算:检索功能
大数据解决方案
Fusioninsight HD:部署在x86架构上
BigData pro:部署在ARM架构上
MapReduce Server(MRS):部署华为云服务上
- 高性能:支持自我研发的存储系统CarbonData
- 易运维:提供了可视化的管理界面
- 高安全:使用Kerborse & Ldap实现认证管理和权限管理
- 低成本:按需购买,自定义配置底层架构性能
HDFS分布式文件系统
HDFS (Hadoop分布式文件系统)
- 创建人:道格卡廷
- 起始原因:开发一个搜索引擎–>存储问题(大量数据的存储)
- google论文: GFS - google自身的分布式文件系统
闭源
HDFS特性
理论上HDFS存储可以无限扩展
- 分布式:把多节点的存储系统结合为一一个整体对外提供服务(提高存储能力)
- 容错性:针对每个数据存储备份(默认3份),备份存储分别存在不同的位置,如果备份或者数据有丢失,会再进行备份,保持一直都是3份
- 按块存储:块大小默认128M, 一个文件可以存储在多个块,
但是一个块只存储一个文件好处:数据丢失针对丢失的数据所属的块,只恢复当前块就可以 - 元数据:记录文件存储在哪些块,块存储在哪里等信息
每个块都有一个元数据信息,并且元数据的大小是固定的150K
HDFS适用场景
- 可以做大文件
- 可以协助离线处理或批处理
- 流式数据访问机制
HDFS不适合做什么
- 不适合大量小文件存储
- 不适合做实时场景
- 不适合随机读写,可以做追加写
HDFS为什么不适合大量小文件存储
(例: 10个文件,每个文件大小为20M)
- 10个文件需要使用10个块,并且每个块只是用了20M空间—> 存储空间浪费
- 有10个元数据,元数据150K
- 寻址时间增长
不适合随机读写,可以做追加写
HDFS系统架构
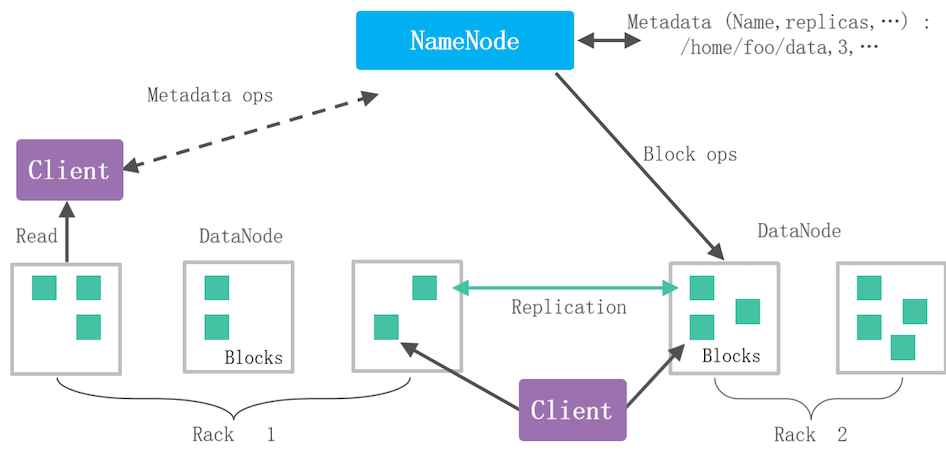
- Client (客户端) :用户接口,用户通过Client连接到组件
- NameNode (名称节点,主节点) :管理DataNode,并且接收用户请求,分发任务,存储元数据信息
- DataNode (数据节点,从节点) :实际处理用户请求,维护自己的Block和实际存储位置映射关系
- Block (块) : 数据存储
HDFS单NameNode的问题
- 单名称节点故障:整个集群都无法使用—>HA(主备配置)
- 单名称节点性能瓶颈问题:并发处理的任务量有限—->联邦机制
HDFS HA特性(主备配置)
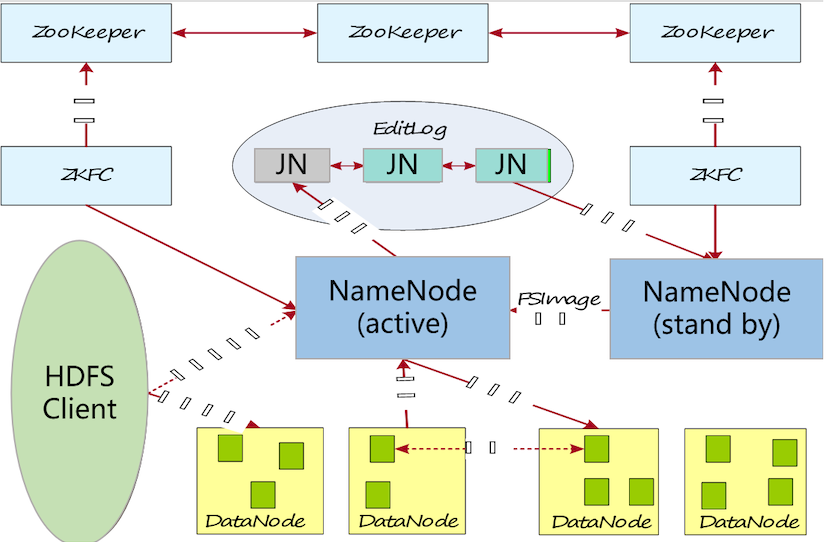
- active节点:对外提供服务
- standby节点:不断备份active节点的数据,
当active宕机,standby会成为新的active - zookeeper监测主节点的状态,一旦发现故障,zookeeper就通知备用节点成为新的主节点
HDFS的联邦机制
各个NN之间是相互隔离的,维护自己的命名空间
HDFS元数据持久化(主备同步)
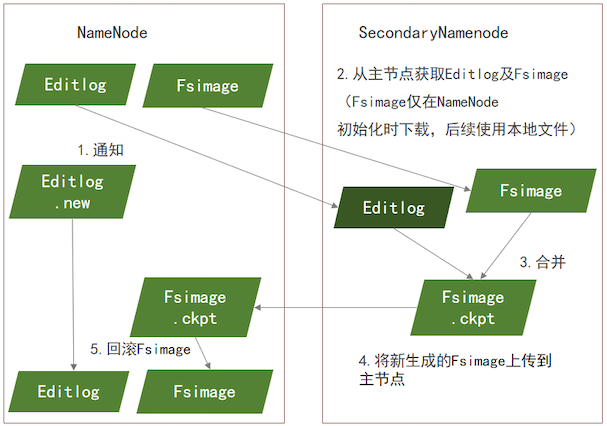
- 备节点会通知主节点新建一个Editlog.new文件, 从这之后的操作都记录在.new文件中
- 备节点从主节点拷贝Editlog、Fsimage文件(只有第一 次需要 下载Fsimage,后续同步使用本地的)
- 将两个文件进行合并,生成Fsimage.ckpt文件
- 备节点将Fsimage.ckpt上传到主节点上
- 主节点接收到Fsimage.ckpt恢复成Fsimage
- 把Editlog.new重命名Editlog
HDFS副本机制 (3份)
- 存储副本规则:
- 第一份副本存放在同一节点中(传输最快,但是如果节点故障,副本也会丢失)
- 第二份副本存放在同一机架的不同节点上(如果整个机架故障,副本也会丢失)
- 第三分副本存放在不同机架的其他节点上
- 副本距离公式:
优先选择的是距离小的
- 同节点的距离为0
- 同一机架不同节点的距离为2
- 不同机架的节点距离为4
HDFS读取流程
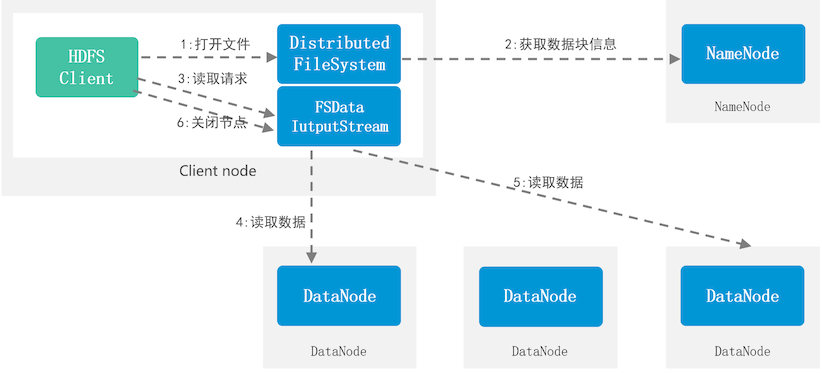
- Client向NameNode发起读取请求
- NameNode接收到请求,反馈对应的元数据信息给Client
- Client接收到反馈请求对应的DataNode
(如果Client本地有数据,优先从本地读取) - DataNode接收到请求,反馈数据内容给Client
- 关闭读取流
HDFS写入流程
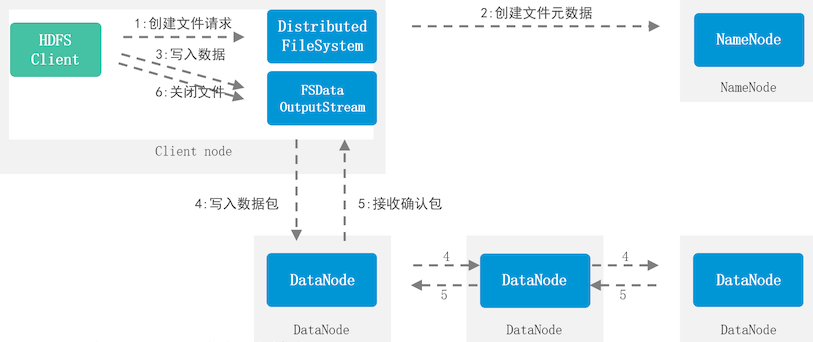
- Client向NameNode发出写入请求
- NameNode接收到请求后生成该文件的元数据信息,反馈DataNode信息给Client
- Client接收到DataNode信息之后,请求相对应的DataNode
- Client提交文件写入到对应的DataNode
- DataNode接收到写入请求,执行写入
- Client写入第一-个节点后,由第一个节点写入第二个节点,第二个节点写入第三个节点
- 写入完成后反馈元数据信息给Client
- 关闭读取流,NameNode更新元数据信息
ZooKeeper
分布式服务应用,可以帮助其他分布式组件协调管理集群
ZooKeeper的特性
- 分布式服务, ZooKeeper集群中有一半以上的节点存活集群才能正常运行
- 最终一致性:所有的节点对外提供的是同一个视图
- 实时性:实时获取、实时反馈应用状态
- 可靠性: 一条数据被-个节点接收到,就会被其他节点也接收
- 等待无关性:慢的或者失效的client请求,不会影响到其他客户端请求
- 原子性:最终状态只有成功或者失败
ZooKeeper集群主从选举/主备切换
- 选举: zookeeper内部投票选举,当节点得到一半以上的票数,它就会称为Leader,其他的节点都是Follower
- 主备切换:当leader出现故障,从其他的follower中重新选举新的leader
ZooKeeper的容灾能力
(可容灾集群最低要求是3个节点)
- 在集群运行过程中允许发生故障的节点数(最大:节点数-半-1)
- 如:集群只要1个节点,容灾能力为0
集群只要2个节点,容灾能力为0
集群只要3个节点,容灾能力为1
集群只要4个节点,容灾能力为1 - 搭建集群时,尽量选择奇数台节点进行搭建
ZooKeeper的读特性
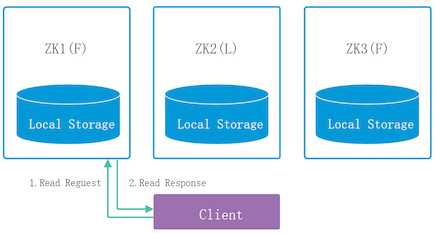
- Client发起读取请求
- 获取到数据(不管接收请求的是Leader节点还是Follower节点)
ZooKeeper的写特性
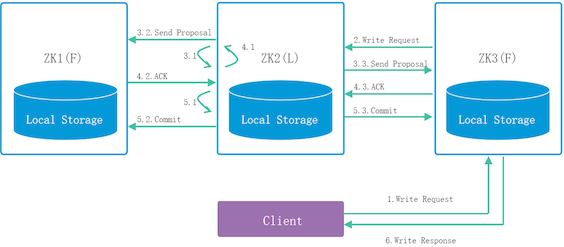
- Client发起写入请求 如果请求到的节点不是leader节点,follower会把请求转发给leader
- leader接收到请求后会向所有节点发出询问是否可以接收写入
- 节点接收到询问请求,根据自身情况反馈是否可写入的信息给leader
- leader接收到一半以上的节点可以写入,再执行写入
- 写入完成后反馈给client,如果Client请求的不是leader, leader把写 入状态反馈给follower,由follower反馈给client
MapReduce
数据处理(数据计算)
创建者:道格卡廷
出发点:搜索引擎-->处理问题google: mapreduce论文MapReduce的特性:分布式计算
MapReduce的特性:分布式计算
- 高度抽象的编程思想:编程人员只需要描述做什么,具体怎么做交由处理框架执行的
- 可扩展性:分布式、搭建在集群上的一-个处理组件
- 高容错性:处理任务时节点故障,迁移到其他节点执行任务MapReduce任务主要分为两大部分: map任务、 reduce任务
MapReduce任务
- reduce任务的处理数据来源是map任务的输出
- map阶段:针对每个数据执行一个操作, 提取数据特征
- reduce阶段:获取到多个map的输出,统一计 算处理,针对key统计汇总这个key对应的value
Map阶段详情
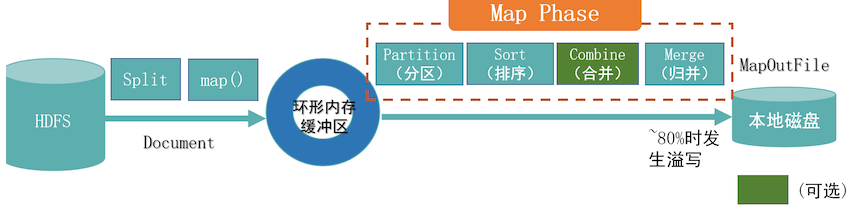
- 数据从数据源获取后进行分片切分、执行map操作
- 分片会被存储在环形内存缓冲区( 当缓冲区达到80%会发生溢写)
- 把分片溢写到磁盘中,生成MOF文件
- 溢写过程中对数据执行
Map阶段详情
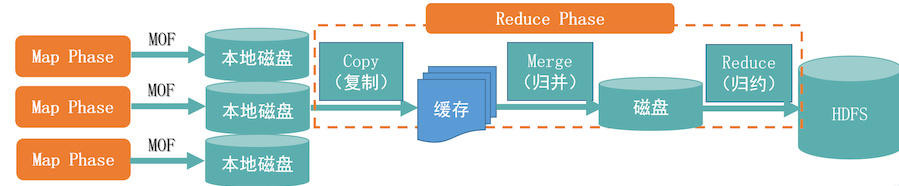
- 把数据(MOF)从磁盘中加载到内存中
- 当数据量过大会执行归并,如果不多,直接跳过归并执行归约操作
- 执行完reduce操作之后,最终结果写入到HDFS
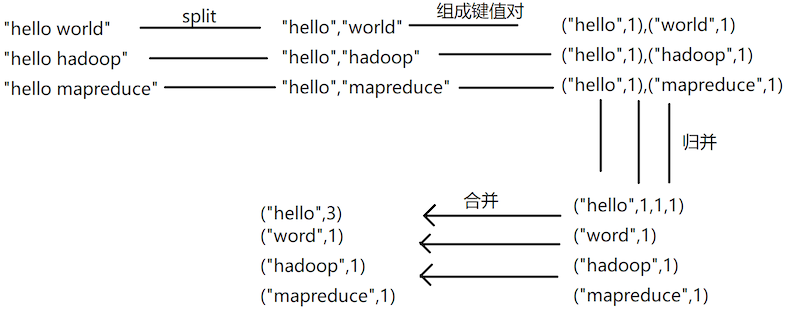
词频统计案例(单词计数WordCount)
- 数据源(很多英文句子或短语的一个文件)
- 提取出每个单词,统计单词出现的次数
MapReduce缺点
- 处理延迟性高
- 使用java语言编程map处理reduce处理
- MapReduce处理任务需要使用资源
MapReduce V1资源调度出现的问题
- 如果发生问题,通知用户介入解决
- 没有区分任务调度和资源调度,都是MR的主节点在处理,主节点的整体工作压力非常大
- 因为资源没有单独隔离,容易出现资源抢占的问题
Yarn
资源调度管理服务---> 可以协助其他组件应用协调管理资源,以及任务调度
Yarn的系统架构
在集群层面来说只有一个ResourceManager, 多个NodeManager
以程序执行层面来说,一个应用只有一-个AppMaster,多个Container
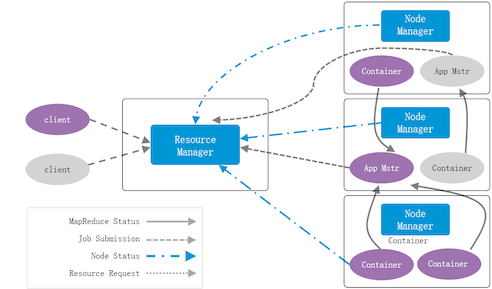
- Client:客户端
- ResourceManager (主节点) :负责资源管理,任务调度
- NodeManager (从节点) :负责提供资源,实际任务执行
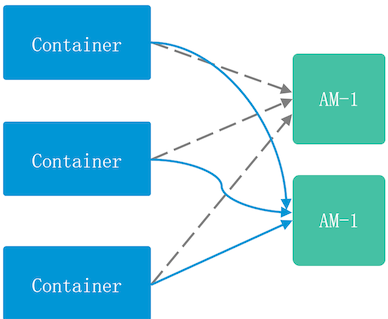
- ApplicationMaster:特殊的Container, 管理同一应用的其他Container,以及实时关注任务执行状态,反馈给RM
- Container:
资源的抽象,被封装起来的资源,一个Container执行一个任务, 其他任务不能使用这个Container的资源
MapReduce On Yarn任务处理流程
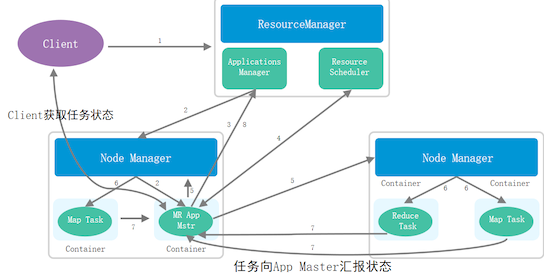
- Client向RM发起请求
- RM(ApplicationManager)接收到请求后在NM中启动一-个AppMaster
- AppMaster接收任务,根据任务向RM (ResourceScheduler) 申请资源
- 在NM中封装资源Container提供给AppMaster执行应用
- 执行过程中Container会实时反馈执行状态给AppMaster
- AppMaster会反馈任务执行状态和自身状态给RM (ApplicationManager)
- AppMaster将运行结果反馈给RM,然后向RM (ResourceScheduler) 申请释放资源
- RM将任务情况反馈给Client
Yarn搭建时支持主备配置,实现主备ResourceManager
AppMaster的容错(当-个AppMaster出现故障,任务管理会被迁移到新的AppMaster)
HBase
HBase分布式列式NoSQL数据库,底层存储使用的是HDFS ,`没有数据类型,所有数据存储都是字节数组的形式byte[]`
创建者:道格卡廷
出发点:搜索引擎-->提高数据读写速度--> BigTable
HBase的特性
- 可扩展性:可以通过添加节点的方式增加数据存储空间
- 高可靠性:底层使用HDFS,能够保证数据的可靠性,预写式日志保证内存中的数据不丢失
- 高性能:处理PB级别的数据
- 面向列: HBase数据存储是面向列的
- 可伸缩性:动态添加列(在添加数据的时候)-
面向列、面向行数据库的优缺点
- 面向行:
优点:能方便快捷的获取一一行记录
缺点:在想要单独获取指定列数据的时候,会检索到其他无关列 - 面向列:
优点:在检索单列数据时,不会出现无关列
缺点:想要查询一条记录时,需要多次IO请求才能拼出一条记录
HBase和RDB (关系型数据库)的区别比较
- 数据索引:
HBase只有一 种索引(rowkey),RDB中可以配置多个索引 - 数据维护:
HBase允许数据增删查,不支持修改,RDB中允许数据增删查改
HBase可以使用覆盖的方式写入数据以此实现数据修改的功能
可伸缩性: HBase可以在添加数据时动态添加列,RDB只能通过修改表的方式添加列
RDB (MySQL) 数据模型:数据库、表、行、列(字段),单元格
HBase数据模型
命名空间、表、行、列(组成列族)、单元格(可以存储多条记录)
- 命名空间: hbase、 default. 自定义(在使用自定义的命名空间时都需要指定命名空间名称)
- 表:由行和列组成
- 行:有一个唯一表示行键(rowkey)
- 列:归属于某一个列族(
动态添加) - 列族:由一个或多个列组成(创建表时创建的,不能动态更改)
- 单元格:由行和列能确定-一个单元格,
一个单元格中可能存在多条记录(多版本记录,使用时间戳进行区分)
HBase的表结构
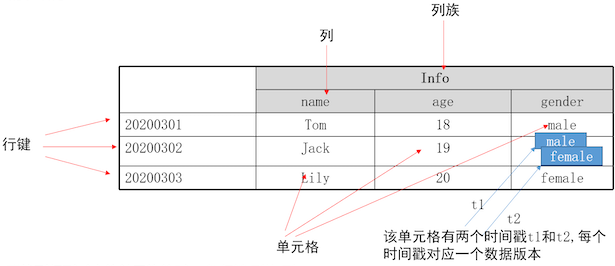
要找到行列对应的单元格值时,表行键,列族:列
默认情况下,只返回单元格中的最新记录,如果要返回多版本需要指定参数VERSIONS=>3
HBase系统架构
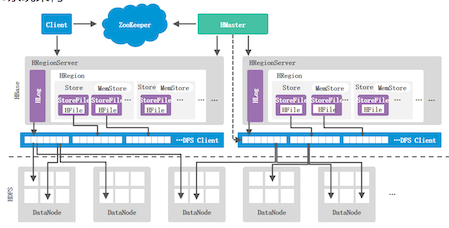
- Client:用户可以通过Client连接到HBase,基本不与HMaster交互
- ZooKeeper:监测HMaster的主备运行状态及主备切换,监测HRegionServer的状态,反馈给HMaster,
存储HBase元数据信息hbase:meta - Hmaster() :管理维护HRegionServer列表,管理分配Region, Region负载均衡
- HRegionServer:管理分配给它的Region,处理用户的读写请求
- DFS Client: HBase连接到HDFS的接口
一个HRegionserver中包含一个HLog, 多个HRegion
HLog:预写式日志WAL,记录数据操作(数据写入之前必须先写入HLog)
Region:
分布式存储的最基本单位,刚开始一个Region存储一个表的内容随着数据增多,Region会不断分裂
Store:一个Region中包含多个Store,一个Store存储一个列族数据
MemStore (写缓存):一个Store包含一个MemStore
StoreFile (磁盘文件):一个Store中包含多个StoreFile
HFile (HDFS文件): 一个StoreFile添加头部信息转换成HFile,最终存储在HDFS中数据写入关键流程:先写入HLog,然后才能写入MemStore,当MemStore达到溢出要求(128M) ,将数据刷写StoreFile中
数据读取关键流程:先读取MemStore,如果没有,再读取BlockCache (读缓存),如果还是没有最终才读取StoreFile
BlockCache存储之前的用户查询过的数据,当MemStore和BlockCache中都没有数据, 需要从StoreFile
中读取数据时,读取完的数据会被加载到BlockCache中
Region拆分
- 拆分原因:数据不断增加,region不断增大, region过大会影响数据读写速度
- 拆分条件:根据行键拆分,尽可能将同一个行键或相似的行键放在一个Region中
-region拆分过程很快,接近瞬间,在拆分时实际还是请求的原文件,拆分结束之后会将原文件内容异步写入新文件,然后之后的请求被转移到新文件
Region定位
元数据信息存储在hbase:meta中,这个表信息被存储在zookeeper内存中通过元数据信息获取Region实际存储位置
HRegionServerBR
H RegionServer出现故障时
- zookeeper发现RegionServer故障,同时HMaster
- HMaster获取故障的RegionServer上的HLog信息,根据与Region的对应关系对HLog进行拆分
- 把HLog存放在Region目录下,把Region重新迁移至其他的RegionServer上
- 其他的RegionServer接收到Region执行重新执行HLog内容
HLog的工作原理
- HLog: WAL预写式日志,数据更新的操作都要先写入HLog中,才能写入MemStore
当MemStore被刷写到磁盘后,会向HLog中写入一条标记记录 (标记记录之前的所有数据都已经刷写到磁盘) - 系统启动时,系统任务先扫描HLog, 检测是否有数据没有写入到磁盘中,如果有先执行写入MemStore,然后再刷写到磁盘,清空缓存,最后再为用户提供服务
如果数据丢失,可以根据HLog重新执行恢复 - 一个RegionServer只有一-个HLog (共用一个HLog)
优点:写入日志时不需要查找对应的Log,直接全部写入一个HLog
缺点:如果RegionServer出现故障, 需要对HLog进行拆分
缓存刷写(把MemStore数据写入到StoreFile中)
- 当MemStore达到刷写条件,就会将内容刷写到StoreFile文件中
- 缓存的刷写是针对整个Region的,当一个MemStore达到刷写要求, 当前的Region下面的所有MemStore都会触发刷写
- 每次刷写都会生成一个新的StoreFile文件(每次的刷写内容都分别在一个新文件中)
- 刷写完成之后会在HLog中写入标记记录,并且清空缓存
StoreFile的合并
(刷写操作会出现大量的StoreFile,且部分StoreFile文件大小过小) 合并比较消耗资源,达到一定阈值才会执行
将多个的StoreFile小文件合并成一个大文件,如果StoreFile文件过大,再进行拆分(根据HDFS块进行拆分)

合并文件会进行筛选:如果本身的StoreFile就已经达到1 00M左右,这个StoreFile是不参与合并的
HBase读取流程
- Client请求zookeeper获取hbase:meta表元数据信息,获取RegionServer信息
- Client请求相对应的RegionServer
- RegionServer接收到请求反馈数据给Client
- 关闭读取流
HBase写入流程
- Client请求的zookeeper,获取hbase:meta表信息,根据写入的行键获取对应的RegionServer信息
- Client请求RegionServer发起写入请求
- RegionServer接收到请求后将数据写入到行键对应的Region中.
- RegionServer反馈写入状态给Client
- 关闭写入流
BloomFilter (布隆过滤器)
判断数据是否存在,如果反馈结果为不存在,是可信的,如果反馈结果为存在,可能有误差
缩小数据违取范围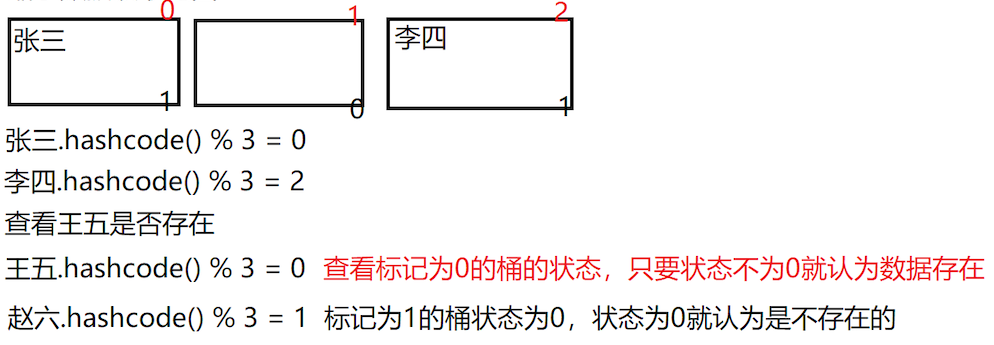
在HBase中行键是以字典序进行排序
HBase Shell命令
1 | namespace: |
Hive
数据仓库,查询分析
Hadoop生态圈
- HDFS存储、 HBase存储提供实时读写功能
- MapReduce并行计算、Yarn资源管理和任务调度
- ZooKeeper协助分布式应用管理服务
- Hive底层使用的是MapReduce做计算,MapReduce的使用对编程人员要求比较高
- 可以执行SQL类的查询分析计算
Hive数据模型
分区:根据字段值进行划分(指定分区字段,分区字段值相同的记录就存放在一一个分区中)
分区在物理上是一个文件夹
分区下还可以再有分区和桶
在创建表的时候可以指定分区字段
分区数量是不固定的桶:根据值的哈希值进行求余放到对应的桶中
桶在物理.上是一-个文件
在创建表的时候可以指定有几个桶表类型:托管表(内部表)、外部表、临时表
托管表(internal) :元数据和数据信息都是Hive在管理删除时,元数据和数据都会被删除\
外部表(external) :元数据由Hive管理,但是数据可以提供给其他组件共享删除时,只删除元数据,数据信息依旧保留\
临时表(temporary) :只在当前会话中生效,当会话结束表就会被自动删除
Hive数据仓库分层(逻辑分层)
- ODS (原数据层,操作数据层) :从数据源获取到的数据
- DWD (数据明细层) :根据ODS做数据清洗得到的结果
- DWS (数据服务层) :根据DWD进行汇总分析计算
- ADS (应用服务层) :根据上层应用的业务需求将DWS数据再一次处理分析得到业务 需要的数据
Hive的分层处理的优势
- 复杂问题简单化:将复杂问题分成多个流程,每个层面执行一-一个流程内容
- 减少重复开发:不要每次提供给上次应用数据时都要对数据进行清洗汇总操作
- 隔离原始数据:减少到原数据的依赖,避免因为原数据的原因,导致后续操作无法执行
Hive SQL的使用
1 | DDL:数据定义语言 |
Spark
Spark特点
轻快灵巧Spark的处理能力是MapReduce的30倍,处理能力不容易受到任务量增加的影响
轻:底层代码只有3万行,使用的函数式编程语言scala
快:处理速度快
灵:提供很多不同层面的处理功能
巧:巧妙的应用Hadoop平台
RDD:分布式数据集、可分区的
- 具有血统机制(RDD由父RDD执行操作之后产生)
- 如果子RDD丢失,RDD故障,重新执行父RDD就可以重新得到的子RDD
- RDD默认存储在内存中,如果内存不足的时候,发生溢写
- Spark节点会分配60%的内存用于做缓存,40%执行内存
依赖类型
宽依赖、窄依赖
- 窄依赖:父RDD的每个分区都只会被
一个子RDD的分区所依赖 - 宽依赖:父RDD的每个分区可能会被
多个子RDD的分区所依赖
Stage划分
遇到窄依赖就加入,宽依赖就断开,剩余的所有RDD被放在一个Stage中
RDD操作类型
创建操作:创建RDD用于接收数据结果
原始RDD:读取数据源获得的RDD (readFile(path))
转换得来:通过父RDD执行操作后得到的子RDD
控制操作:持久化RDD,可以持久化到内存或磁盘中,默认存在内存
转换操作:可对RDD执行的处理操作,转换操作是懒惰的,转换操作并不是立马执行,遇到行动操作才执行
行动操作:实际调用Spark执行(存储文件,数据输出等)
transformation算子在整个程序中 ->声明转换操作,实际并没有执行
action算子时, 会从第一-个操作开始执行
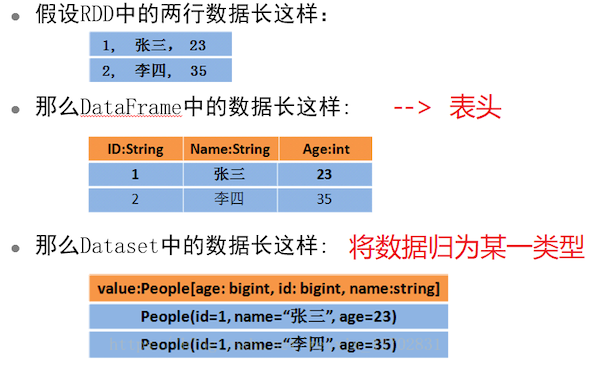
DataFrame:属于一个DataSet实例, 不可变的弹性分布式数据集,存储数据时不止存储数据内容,存储数据对应结构信息及类型
DataSet:以对象的形式存储数据集,DataFrame= DataSet[Row]
RDD、DataFrame、 DataSet数据集的联系
Spark体系架构
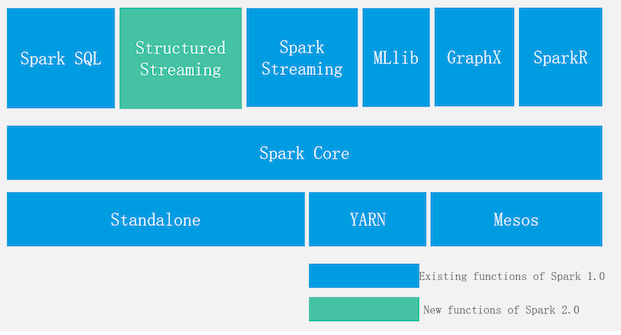
- 集群部署形式:
Standalone: spark自 己管理资源调度
Spark On Yarn:使用yarn做资源管理调度
Mesos: AMR实验室开发的资源管理器,最适用于Spark的资源管理器 - Spark Core:处理核心
- Spark SQL:处理结构化数据,使用Hive元数据
- Spark Streaming:实时流处理(实际微批处理) , 能够低延迟的计算反馈结果
- MLLib:机器学习,根据历史数据进行建模,根据模型和提供的数据进行数据预测
- GraphX:图计算,主要用于关系统计,关系查询
- SparkR: R语言库,提供R语言接口,可以使用R语言操作Spark
- Structured Streaming:流处理,将数据存入-个无边界表(新数据不断添加,旧数据不断移除)使用增量的方式获取表数据内容进行执行
Streaming
分布式流处理组件
关键特性:实时响应,延迟性低
- 数据不存储先执行(离线处理先存储数据然后再执行)
- 连续查询(程序运行后就不终止,除非系统故障导致的终止或者手动停止)
- 事件驱动:传入的数据信息触动任务处理
Streaming系统架构
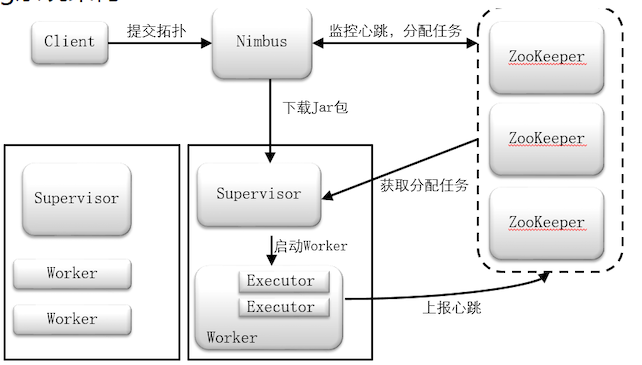
- Client:客户端接口
- Nimbus (主节点) :接收客户端的请求,管理Supervisor从节点,管理任务分配,编写任务书
- Supervisor (从节点) :实行任务,管理worker
- Worker (进程) :程序执行
- Executor (线程) :每个Executor中默认执行一 一个Task
- Task (任务) : Task分别对应每一 个Spout/Bolt组件的执行
- ZooKeeper:监控Nimbus主节点的状态,如果主节点故障切换备用节点
监控Supervisor从节点状态,如果从节点故障,通知Nimbus迁移任务,启动自动恢复
接收Nimbus任务书,将每个从节点的任务存放在每个Supervisor自己对应的目录中
Streaming任务架构
- Topology:拓扑结构,封装任务执行流程
- Spout:发送数据源的组件,接收第三方数据收集I具提供的数据发送到数据流
- 每个应用只有一个spout
- Bolt:从数据流中获取数据,执行数据处理,如果当前bolt不是最后-个执行程序将结果放回数据流一个应用中可以有多个bolt
- Tuple:数据流中的数据格式,组件之间数据传输的格式,元组中包含两个参数(id, stream)
Streaming执行任务
- 用户通过Client提交应用到Nimbus中
- Nimbus接收到应用后,根据应用情况及当前集群的从节点情况编写任务书
- 将任务书.上传到ZooKeeper中
- ZooKeeper接收到任务书后根据每个节点将对应的任务存放在节点对应的目录下
- Supervisor周期性监测自己在ZooKeeper中的目录有没有新任务
- Supervisor发现新任务,根据任务书内容从Nimbus中下载任务所需要的jar包
- Supervisor执行任务,反馈执行状态给Nimbus .
- Nimbus将任务状态反馈给Client
根据任务架构执行
- 获取拓扑结构
- 根据拓扑结构分别找到每一流程的处理单元
- 按照路程执行处理单元
消息传递语义
- 最多一次:数据发送只发送一次, 可靠性最低,吞吐量最大
缺点:可能存在数据丢失的情况
优点:数据一定不会被重复执行 - 最少一次:数据可能会发送多次,可靠性高,吞吐量较小
优点:数据不会丢失
缺点:数据可能会被重复执行 - 仅有一次(精准一次) :数据就发送一-次, 并且保证发送成功,可靠性高,吞吐量最低
优点:数据不会丢失,且数据不被重复处理
缺点:消耗的资源和时间较多
Ack机制(消息传输最少一次)

Flink
分布式实时计算引擎(流处理引擎)
Flink VS Spark Streaming
- Flink可以做流处理(侧重)也可以做批处理,底层引擎属于流处理引擎
- 通过流处理引擎模拟批处理形式实现的批处理
- Spark可以做流处理也可以做批处理(侧重点),底层弓|擎属于批处理引擎
- 通过批处理引擎,模拟流处理实现的流处理功能
Flink的关键特性
状态、时间、窗口、检查点
Flink系统架构
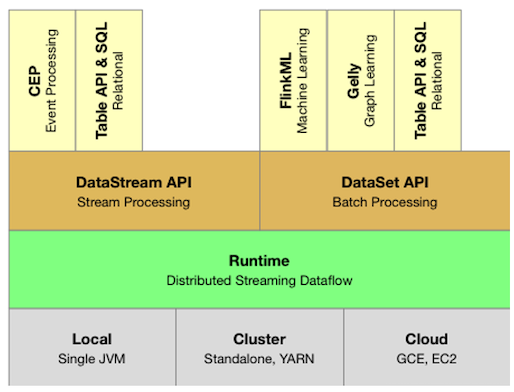
- 部署形式: Local (单机版部署)
Cluster (Standalone: Flink集群自己管理资源调度
Yarn:借助Yarn组件帮助管理协调资源和任务)
Clound (云部署) - Flink核心模块: Runtime (不管是流处理还是批处理都是在Runtime中执行)
- 接口层: DataStream (流处理)和DataSet (批处理)
- Table API & SQL:处理结构化数据
1
2
3
4
5Table API:将操作应用封装成方法
select("t_ demo ").where("条件")
SQL:基于Table API使用,
sqlQuery("select * from t_ demo where条件")
有界流和无界流
- 有界流:知道开始,知道结束,使用批处理处理有界流数据.
- 无界流:知道开始,不知道结束,使用流处理接口进行数据处理
DataStream:用于存储数据的数据集,只能执行流处理操作
- 基于流处理运行环境获取到的数据
DataSet:用来接收数据的数据集,只能执行批处理操作
- 基于批处理运行环境获取到的数据
并不能在一个应用中同时接收流处理和批处理接口,以此实现流处理和批处理的共用
Flink运行流程

- DataSource:接收数据输入,从数据源获取数据
- Transformations:数据转换,数据处理过程
- DataSink:将最终数据结果输出到指定位置(如HDFS、 HBase、 文件、数据库等)
Flink程序运行流程
1. 创建运行环境流处理/批处理
2. 通过运行环境对象获取数据源数据(DataStream/DataSet)
3. 针对数据集进行数据转换
4. 将最终结果进行输出(批处理的print算子)5. 最后执行程序(行动算子) executor()
Flink运行程序
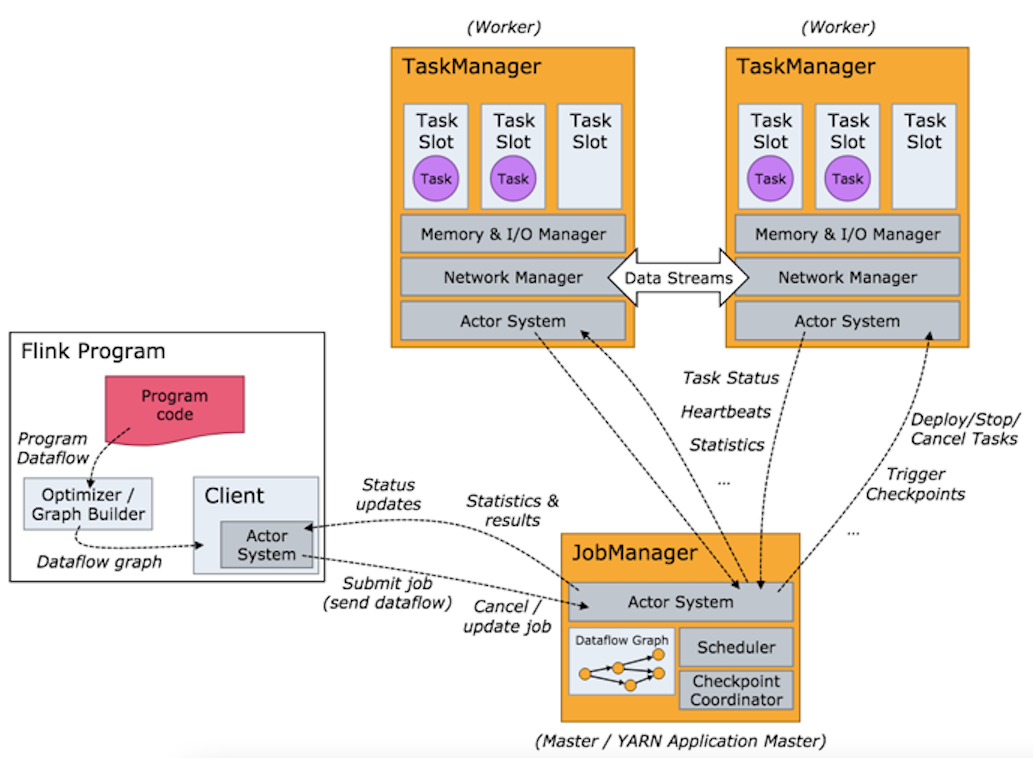
- Client向JobManager发起请求
- Client对任务进行优化等操作
- JobManager分配任务给TaskManager
- TaskManager接收到任务后执行任务
- TaskManager反馈任务执行状态给JobManager
- JobManager统一反馈给用户
- Flink Client:用户通过Client连接到JobManager
- JobManager (主节点) :接收用户请求,管理资源任务分配,管理从节点信息
- TaskManager (从节点) :接收任务处理任务,反馈给主节点
- Standalone部署:创建Task Slot: Flink的抽象资源
Flink状态
区别于其他组件的一-个特性,支持状态管理(中间结果状态)
Fink窗口类型
- 滑动窗口: 窗口移动方式是平移,设定参数时需要设定窗口大小,滑动距离.窗口大小固定,可能会出现数据源重复和数据丢失的情况
- 滚动窗口: 窗口移动方式滚动,滚动距离就是窗口大小,设定窗口时只需要设定窗口大小.窗口大小固定,不会出现数据重复或者数据丢失的情况,会出现空窗口的情况
- 会话窗口: 由会话启动的窗口,设定过期时间,窗口代销不固定,运行时不会有丢失的数据,不会出现空窗口
- 时间窗口: 以时间为条件设定的窗口,
分别可以再分为滑动或滚动 - 数量窗口: 由会话启动的窗口,设定过期时间,
分别可以再分为滑动或滚动
Fink的时间类型
- 时间类型: 事件发生的时间
- 时间类型: 时间达到处理系统的时间
- 处理时间(默认): 时间被处理的时间
- 时间乱序问题: 事件被处理的顺序不是时间产生顺序
- 时间乱序原因: 数据受到数据传输影响
Watermark(水位线/水印): 解决数据乱序问题
- 设定水位线时间,当水位线设定的时间时间也达到系统时,就会触发窗口执行
- 可设置水位线延迟,可允许窗口延迟触发\
对于延迟数据的处理方式
- 丢弃(默认): 当窗口已经被触发过,该窗口的数据达到也会被丢弃,不会被执行
- 可允许延迟: 设定可允许延迟时间,窗口已经被执行,但是输在可允许延迟时间达到,重新重发窗口的执行
allowedLateness(可延迟时间) - 收集后做统一处理: 把所有的延迟数据收集起来,在程序最后做统一处理
OutputTag<T> lateOutputTag = new OutputTag //用于存放延迟数据的数据集.side0utputLateData(late0utputTag)
Flink容错性 (CheckPoint实现)
CheckPoint:检查点,自动触发,当任务结束后会自动删除- 保存当前任务状态,周期性触发,默认情况下不启动检查点
- 在启动检查点时就可以设定周期时间,单位ms: .enableCheckPointing(10000)
- 修改消息传输语义(默认情况仅有一次): .setCheckPointMode(CheckPointMode.AT_LEAST_ONCE)
- 快照超时时间:防止一个问题快照影响大量快照创建堆积: .setCheckpointingTimeout(60000)
- 可以设定检查点之间的最小间隔时间
- 可以设定最大并行执行数量
- 设定外部检查点:可以把检查点信息存储于在外部系统中,不会因为Flink系统问题受到影响
- SavePoint:保存点,底层CheckPoint, 手动触发,任务结束后也依旧保留
状态保存
内存:默认,state和checkpoint都存储在内存,只是用本地测试
文件系统: state在内存, checkpoint在文件系统中
数据库: state存储在内置数据库中,checkpoint在文件系统中,针对大量数据任务处理的场景
Flume
Flume属于一个高性能、分布式的海量日志采集工具可以适用于流数据采集、也可以用于静态数据采集
Flume基础架构
(主用应用于单节点数据采集)
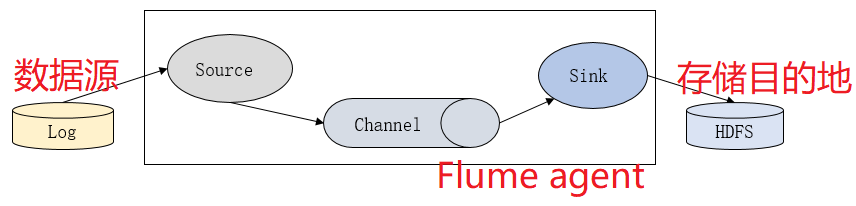
- Flume中有两个组件对外交互: source、 sink
- source:采集数据,接收数据输入
- channel:管道、 临时存储
- sink:数据输出
Flume多agent架构
(主要用于集群外采集传递到集群内采集)

- 把第一级的Flume数据输出到第二级Flume中
- 设定第一-级Flume的sink类型为avro协议或者thrift协议可以将数据存储到下一级Flume的Source
Flume多Agent合并
(将多数据源采集到的数据汇总处理)
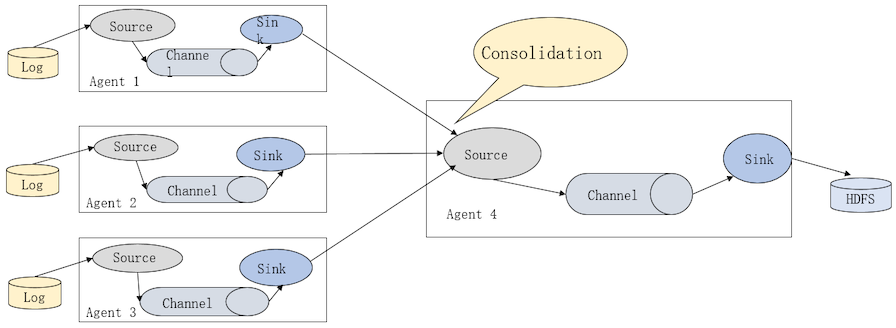
Flume数据传输基本单位
- event: 基本单位,header+ byte[]
- 当source采集数据时,在source内部将数据封装成event
Flume Agent原理
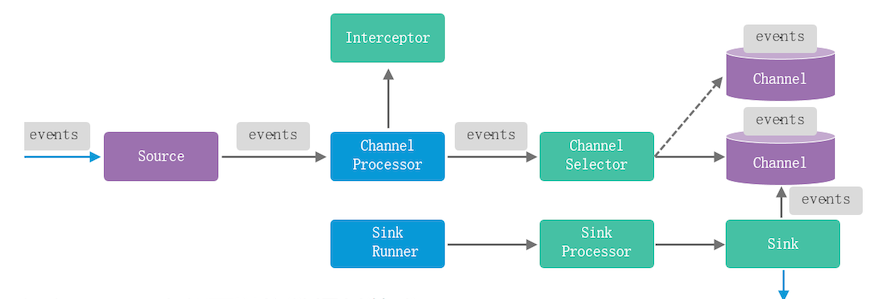
- 在source内部可以将数据封装成event
- source将event传输给channel处理器(拦截器)可以做数据简单处理
- 清洗完后的数据通过channe|选择器将event输入到指定的channel
- SinkRunner在程序运行时就启动
- 使用sink处理器实例化一个指定类型的sink从指定的channel中抽取数据
- 将抽取到的数据按照设定的类型和目的路径将数据输出
Flume Source
(数据收集、接收数据输入)
- 驱动型:被动接收数据输入
- 轮询型:周期性的主动扫描是否有新数据产生
Flume Channel
(数据存储)
MemoryChannel (内存) : event数据存放在当前节点的内存中
读写速度快,数据未持久化,占用内存空间
capacity:最大内存容量(默认情况下使用到节点内存存满为止)FileChannel (文件) :使用WAL,管理上比较复杂
数据可持久化,数据读写速度慢于内存形式JDBCChannel (内置数据库) : derby数据库,可以替代File存储的形式
数据可持久化,数据读写速度慢于内存形式
Flume Sink
(数据输出)
Flume的Source、Channel、 Sink之间的关系
一个Source至少连接一个Channel一个Sink只作用于一个Channel
Flume级联节点
级联节点间传输的数据可以进行加密、压缩
- 加密:提高数据传输安全性
- 压缩:提高整体传输速度(减少传输时间)
Flume内部数据传输(source --> channel --> sink) 不需要加密
Flume运行实例
内容需要配置到配置文件中(自定义.properties)
1 | a.sources= r1 |
Flume运行命令
1 | flume-ng agent --name a --conf flumecï 71411Z --conf-file 配置文件 - Dflume.root.logger=info, console |
Kafka
分布式日志系统(发布订阅消息系统),可分区、多副本、多订阅
消息传输形式
- 点对点:数据在被获取到之后就会被从消息系统中删除(只有-一个用户可以获取到这个消息)
- 发布订阅:消息发布之后,就算被用户获取之后也不会删除,依旧保留在系统中提供给其他用户获取
Kafka的特点
- 可支持TB级别的数据也能在常量时间内的访问性能
- 高吞吐率:单节点每秒可以传输100K条数据
- 可分区:数据以分区形式存储
- 多副本:提高数据容错性
- 同时支持流处理和批处理
- 可扩展性:本身属于集群由多节点组成,扩展节点
Kafka拓扑结构
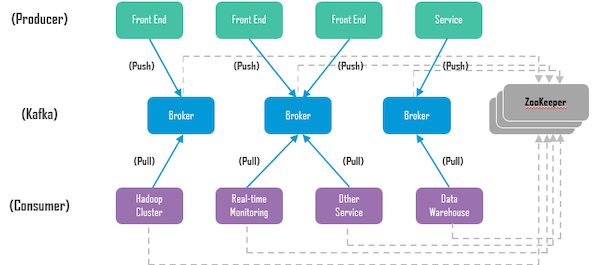
- Kafka:由broker集群组成
- Producer:数据发布者,发布消息,将数据发布到Kafka中存储
- Consumer:数据消费者,订阅消息,从Kafka中获取数据
- ZooKeeper: Kafka强依赖,监测集群状态
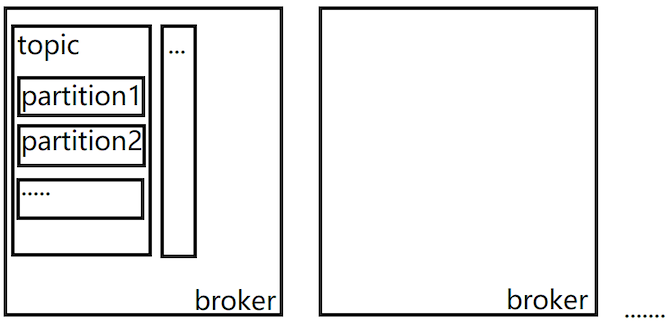
Kafka集群系统架构

消费组:consumer group
每个消费者一定是属于某一个消费组
- 消费数据规则:消费组内的数据是竞争的,消费组间的数据是共享的
一条消息可以被多个消费组获取,但是每个消费组只能有一个消费者消费信息 - Kafka Topic:消息类别名
用于区分记录数据、发布者发布数据时需要指定topic,消费者订阅数据时指定topic - Kafka Partition:分区,数据写入:顺序追加的方式
数据以分区的形式存储,在创建topic时可以指定当前topic中有几个分区 - Kafka Segment:分段
每个消息就是一个分段, 分段由两个文件组成.index和.log - Offset:偏移量值
每一个消息都有的唯一标识位置 - 每个消费组都会维护一份offset文件(当前组中的成员读取的数据位置)
- 读取数据时数据定位: broker –> topic –> offset
Kafka的其他重要概念
- replica:副本,在创建partition的时候指定该分区有几个副本\
–partitons 1 –replaction-factor 2
数据文件为2份,partiton本身也属于副本的一部分
- leader:从副本中选取一个leader对外提供服务,发布者和消息者只跟leader交互
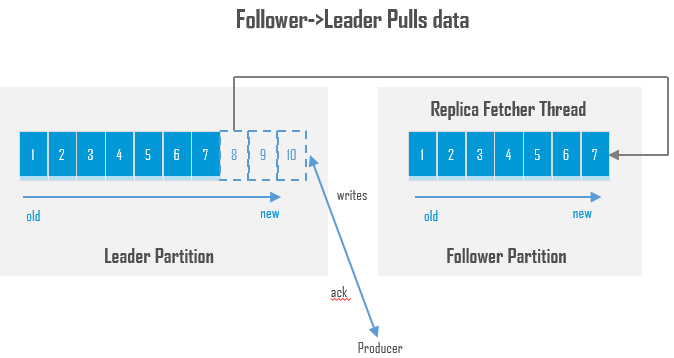
- follower:除leader以外的其他副本都是follower, follower同步leader信息
- controller: kafka中的一 -个服务器: leader选举、 leader切换
- ISR列表:列表中的follower,能正常同步leader信息
只有在列表中的follower有资格成为下一-任leader
刚开始所有的follower都在ISR列表中,当follower故障不能及 时同步leader时会被移除列表
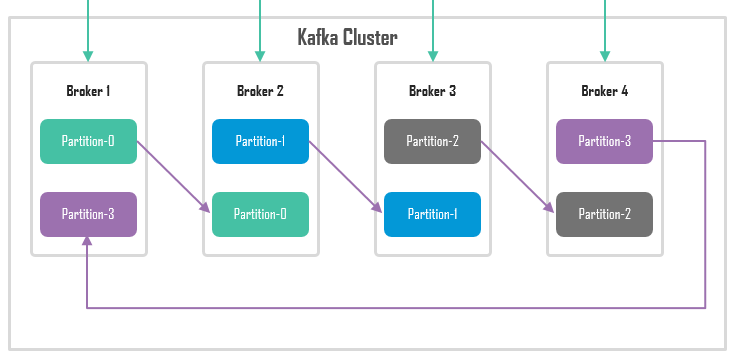
Kafka分区副本
(节点和节点之间的分区互为主备)
分区副本同步
(follower从leader同步数据 )
- 如果所有分区都出现故障
可靠性高、恢复速度慢:等待ISR中的分区恢复,第一个恢复就是leader
可靠性低、恢复速度快:等待分区恢复,第一个恢复的不管是不是ISR列表中的分区也成为leader - 可靠性传输:幂等性(操作一次和多次的结果是一样)
给每条消息一个唯-标识id, 消息传递后使用一个列表记录已传输成功的消息id
每条消息传输到达时都会被使用id在列表中查询,查看id是否存在
如果存在:说明消息之前已经被传输过
如果不存在:正常处理,并且处理完后将id写入列表 - acks机制(检测数据是否发送成功)
acks=0:不管数据是否发送成功
acks=1:当数据写入leader时就认为成功
acks=all:当数据写入leader并且follower都接收到才反馈成功 - Kafka持久化存储数据(不管数据有没有被消费过)
- 旧数据的处理方式:删除/压缩
删除:配置数据过期时间
压缩:根据键值对的key值只保留最新的value值,以前的值就删除 - Kafka高吞吐的原因
顺序读写:数据以追加形式写入分区,速度远快于随机读写
零拷贝:数据写入不需要经过数据缓冲区直接到达磁盘
分区:数据可以分别存在多个分区中,读取的时候可以并行的从分区中读取到数据
压缩:可以对数据进行压缩
分区副本:只有leader对外提供服务的, follower只做同步操作
Loader
基于开源的Sqoop组件开发得到的
Loader
- Loader数据导入导出(作用在关系型数据库和非关系型数据库之间)
关系型数据库:结构化
非关系型数据库:非结构化 - 数据导入:数据从RDB导入到NoSQL
- 数据导出:数据从NoSQL导出到RDB
- Loader相比较Sqoop组件的增强特性
图形化:提供WebUI界面可以通过界面配置任务,连接器的配置MRS (Hue)
高性能:底层使用MapReduce并行处理
高可靠:主备双机的搭建
作业失败后允许重试
作业失败后不会有残留的数据
安全性:使用kerberos进行安全认证
Loader模型架构
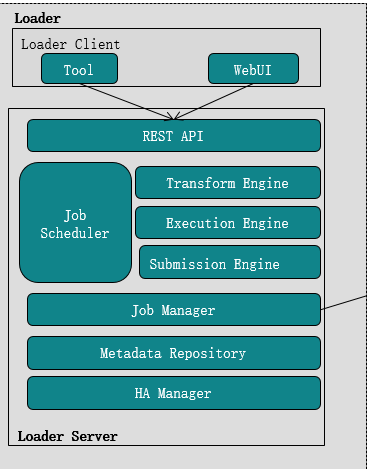
Loader Client: Tool: 命令行模式连接Loader服务
- Web UI: MRS图形化的方式连接到Loader
Loader Server:
- Restful API (http+json) 对外提供的连接接口
- JobSheduler: Transform 转换模块–>数据处理.
Execution执行模块–>执行计划
Submission提交模块–>提交到MR
JobManager:管理任务执行状态 - Metadata Repository:元数据仓库,存储管理元数据
- HA Manager:主备管理
Loader任务执行
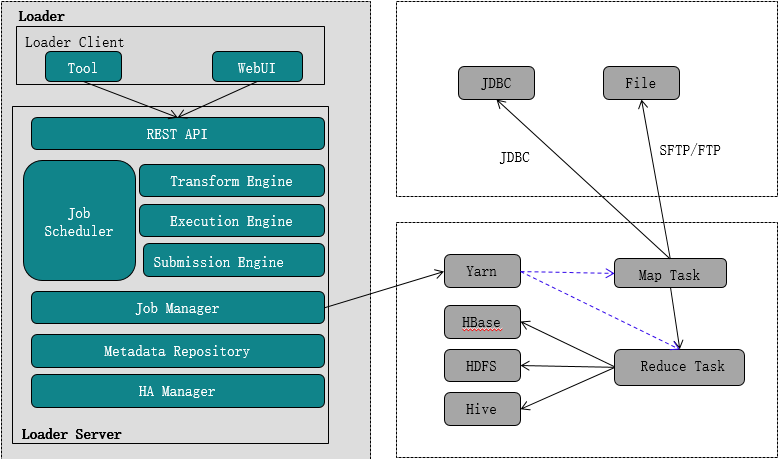
- Client提交任务
- Loader任务计划
- 将任务提交给Yarn
- Yarn调配资源将任务分配为Map或Reduce任务执行
- 将数据存入设定的存储介质中
Loader任务配置
- 输入:数据来源的配置
- 转换:字段映射、获取数据、过滤数据、并发执行数量
- 输出:数据最终输出目的地的配置
ElasticSearch
分布式检索服务,适用实时场景
Hive:可以做查询分析,底层MR处理,不适用实时
ElasticSearch特点
- 基于Lucena扩展
- 可以水平扩展
- 原型环境和生产环境可以无缝切换
作为非关系型数据库NoSQL数据库使用- 支持结构化数据和非结构化数据
索引
正排索引:在文件中查找关键字
扫描每个文件内容找到跟关键字相关的文件,返回文件倒排索引:根据关键字查找文件(提前给文件设定关键字)
根据关键字查哪些文件标记了这个关键字
快速查找相关文件,并且文件相关度更高
ElasticSearch系统架构
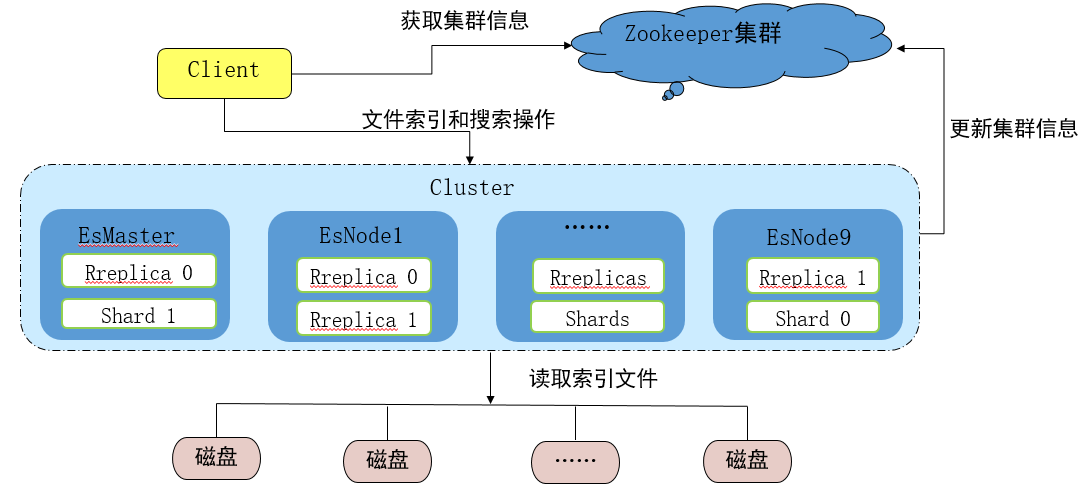
- Client:连接到ZooKeeper获取集群信息,连接到集群
- EsMaster:主要任务分配,管理EsNode信息, 不参与分片级别的数据检索
- EsNode:处理用户管理索引|操作,管理自身分片信息(数据默认存储在内存中)
- ZooKeeper: es强依赖,管理集群状态,并且记录集群信息
ElasticSearch中的核心概念
- 索引: index –> 命名空间
- 文档: document –> 数据存储,ES中的检索基本单元
- 映射: mapping –> 约束字段类型
ElasticSearch命令使用
1 | 数据添加/修改: put /索引/_doc/id |
Redis
基于内存的,网络高性能数据库
- 读取速度快,低延迟
- 适用于实时场景
- 可持久化(RDB/AOF)
- key-value
key命名:见名知意
value:可以存储多样数据 - 属于NoSQL数据库(存储多样化:图像、视频、音频、数字、文字等)
Redis应用场景
- 排序类应用
- 设置过期时间应用
- 统计计数
- 消息队列
- 临时存储
Redis系统架构
无中心、自组织的集群: 集群中的所有节点会维护一个集群拓扑- 分桶:根据key值计算hash存储进不同的槽中
- 集群拓扑中维护的就是槽和节点的映射关系
Redis节点只帮助用户重定向,不进行转发
重定向: Client发出多次请求(Client分 别请求节点)
转发: Client只需要请求第一个节点,节点帮助Client向正确的节点发出请求(Client只需要请求第一 台节点)
Redis读写流程
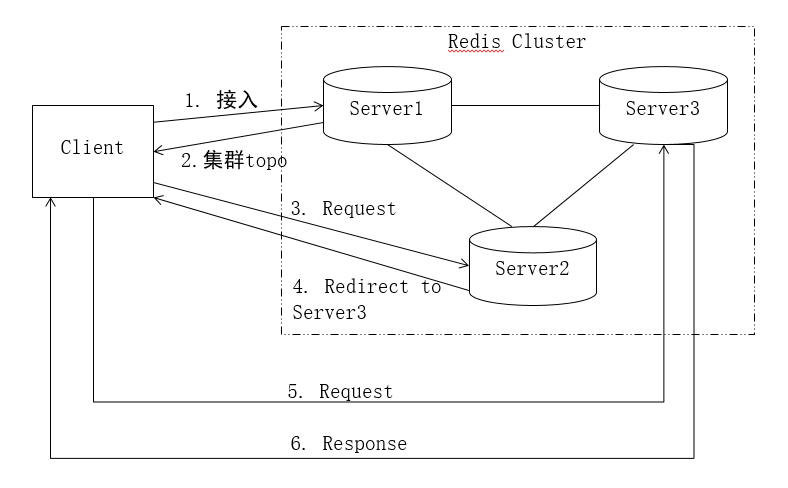
- Client向任意一 个节点发出请求,连接到redis
- 从redis节点中获取redis集群拓扑,得到key存储的server信息
- 可以获取到key对应的槽所在的server信息
- 如果做读取,对server发起读请求,如果是写入,就发起写请求
如果在Client获取拓扑时,数据发生变动,从一个节点迁移到另-一个节点- 此时Client获取到的是旧的拓扑,向原定的server发起请求
- server接收到请求后发现Client要请求的数据已经被迁移,会告诉Client数据被迁移到哪个节点
- Client从原server中接收到正确server的反馈信息
- 对新server重新发起一-次请求,获取数据响应
Redis关键特性
- 支持多数据库
名称不支持自定义,从0开始递增
默认情况下支持1 6个数据库,不做更改的情况下使用的是0号数据库
如果要切换当前使用的数据库:select 0 - 可以通过正则表达式匹配所有符合规则的key值
keys正则表达式
要查找所有的a开头后面跟数字的所有的key值:keys a[0-9]* - 判断key是否存在:
exists key - 删除key值:
del key key2 - 获取key对应的类型:
type key redis中不区分大小写( 单个单词要不就全大写要不就全小写)
Redis数据类型及使用
- String的数字可以作为数值类型使用
- Hash添加数据时value是键值对(应用于对象数据存储)
- List可重复的有序集合
操作数据时可以区分左右(前后)查询整个集合中的数据时lrange key 0 -1 - Set不重复无序的集合
可以针对集合计算交集、并集等 - Sorted Set:有序集合,可以根据给key的分数进行排序
Redis性能优化
- 可设置key的生存时间
- Redis管道(pipeline) –> 管道数据传输速度快于普通传输(仅在Java API中)
- 数据排序Sort,如果是对集合进行排序Sorted Set
- Redis持久化(RDB/AOF)
RDB(默认) :使用快照的方式对当前数据进行持久化存储
创建快照的条件(在指定时间内有指定数量的key发生变化):save 时间s数量
手动触发: sava、bgsave
save:使用主进程运行,在创建快照过程中会堵塞其他进程运行
bgsave:划分一个子进程用于执行快照,不会影响其他得到进程运行
AOF:使用的日志文件形式存储信息
可以设定数据发生变更时进行记录\ - Redis内存占用情况
相同数据的情况下,32位操作系统比64位所使用的内存更少
100万条简单键值对,占用100M空间,实际占用空间较少,可存储数据量较大
Redis的优化
- 精简键名值数据:尽可能简单,但是能知意–>
可以节省存储空间 - 在不需要持久化的应用场景中关闭持久化功能
- 内部编码优化
- SlowLog:记录运行超时命令系统
- 修改Linux内核内存分配策略: 1:不需要检验内存情况,可以直接运行任务直到内存使用完为止
- 关闭THP:节省资源开销(redis修改时先复制再对复制内容修改)
(THP:如果数据只有200K,使用THP的情况下,这个大页大小约20M
不使用THP时,复制后总大小400K,使用了THP复制后总大小40M) - 修改linux中的tcp最大连接数
- 限制Redis使用内存大小
- 做多条数据操作时,尽量选择批量操作命令不要通过循环执行
安全认证&权限管理Kerberos & Ldap
在大数据平台中,统一身份体现在:只要通过用户名和密码成功登陆,就可以操作授`权过的组件`
统一用户管理系统:用户及相关权限管理、用户登录后的相关管理等
统一身份认证管理系统
- 管理模块:管理信息存储,管理认证,用户请求
- 信息存储模块:存储用户信息、权限信息
- 认证模块:通过用户请求和当前系统存储的用户信息做比对,确认用户是否正确、核查用户权限
Ldap目录服务系统
- 目录:加快数据检索速度
- 轻量级目录访问协议、跟踪协议
LdapServer系统结构(树状结构)
- 树状结构中会包含很多节点,每个节点都有自己的名称dn(当前节点及它的所有父节点)
- 根节点名称是dc,标记为区域
- 区域的下一级是组织,组织节点名称: ou
- 组织节点下一级是对象,对象节点名称: cn,存储对象属性
Ldap功能模块设计
- 查询类操作
- 更新类操作
- 认证类操作
- 其他操作:放弃服务或者扩展服务
Ldap集成设计
- 身份认证架构设计
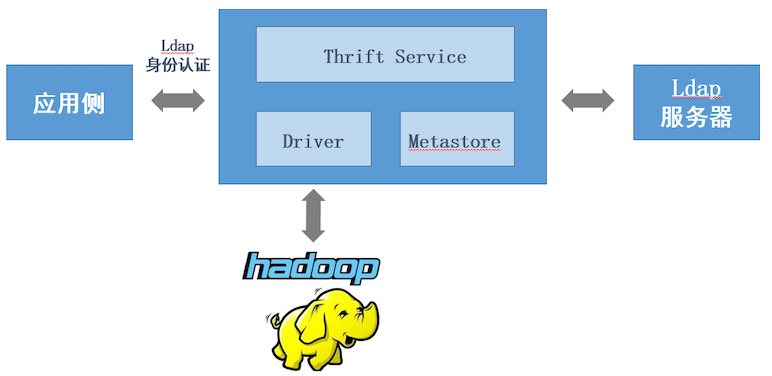
身份认证流程设计
- 应用侧提交认证请求
- Thrift Server从Ldap获取相关用户信息
- Thrift Server执行认证比对
- 认证成功后将请求导向响应的应用
身份认证功能设计
可以通过组Group和角色Role的方式给用户赋予权限
Group:设置组权限,将用户添加到组中
Role:给角色设定权限,给用户匹配角色
Kerberos认证处理
- krbServer中的三大核心: Client 、KDC、 KDC Server
- Client :接收用户请求
- KDC:生成密钥,发放密钥等
- KDC Server:提供密钥服务
Kerberos应用流程
- 用户提供用户名和密码给登录认证系统
- 登录认证系统通过登录认证后,反馈一个当前用户的用户信息卡 (用户、密码、所授权信息)
- 用户获取到用户信息卡之后就可以进入到MRS中.
- 在MRS中找到对应的要使用的组件,提交自己的信息卡
- 组件对比信息卡查看是否具有当前组件的权限
- 用户前往权限授权中心,提交信息卡,权限授权中心根据信息卡对指定组件进行授权(ST)
- 用户获取到对应组件的授权信息,可以再次向组件发起请求(信息卡, ST)
- 组件接收到请求后再次校验,校验结果没问题的话,用户就可以正常使用组件